Bash Commands That Save Me Time and Frustration
Bash Commands That Save Me Time and Frustration
Here’s a list of bash commands that stand between me and insanity.
This article will be accompanied by the following github repository which will contain all the commands listed as well as folders that demonstrate before and after usage!
to accompany the medium article I am writing. Contribute to bgoonz/bash-commands-walkthrough development by creating an…github.com
The readme for this git repo will provide a much more condensed list… whereas this article will break up the commands with explanations… images & links!
I will include the code examples as both github gists (for proper syntax highlighting) and as code snippets adjacent to said gists so that they can easily be copied and pasted… or … if you’re like me for instance; and like to use an extension to grab the markdown content of a page… the code will be included rather than just a link to the gist!
Here’s a Cheatsheet:
Getting Started (Advanced Users Skip Section):
✔ Check the Current Directory ➡ pwd:
On the command line, it’s important to know the directory we are
currently working on. For that, we can use
pwd command.
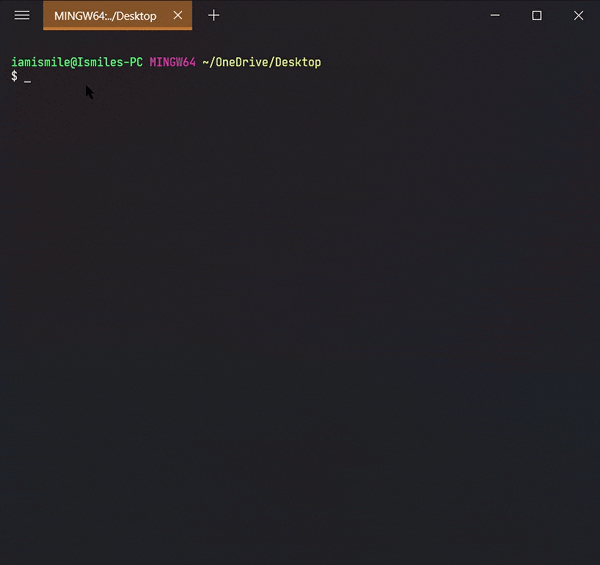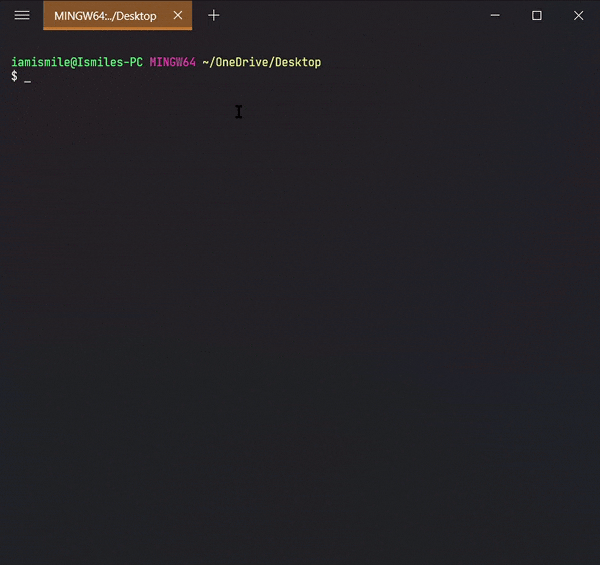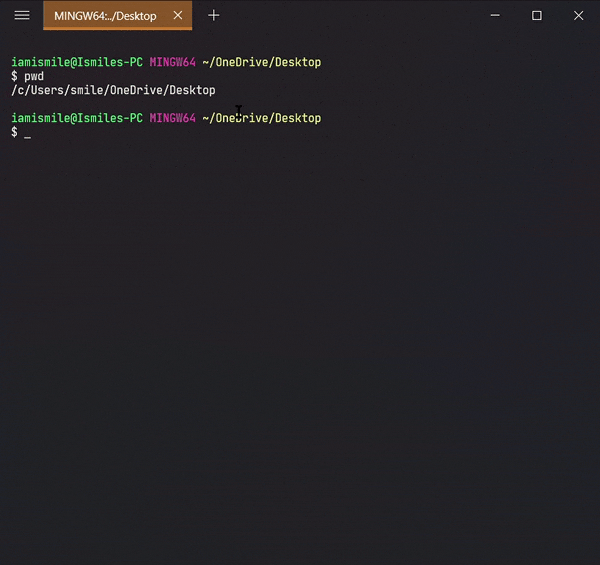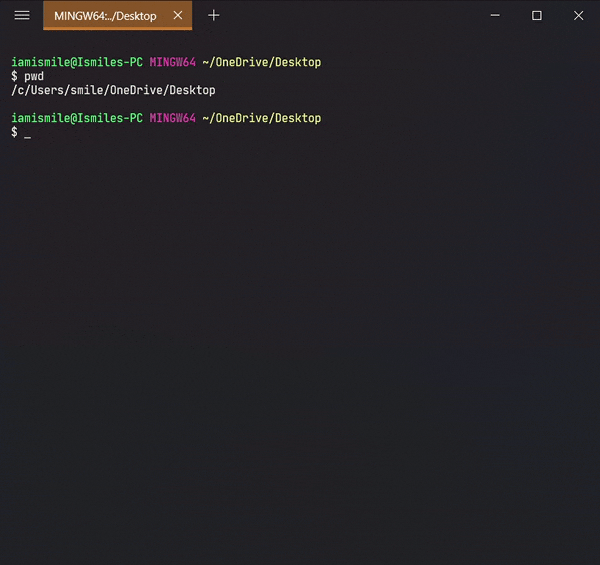
It shows that I’m working on my Desktop directory.
✔ Display List of Files ➡ ls:
To see the list of files and directories in the current
directory use
ls command in
your CLI.
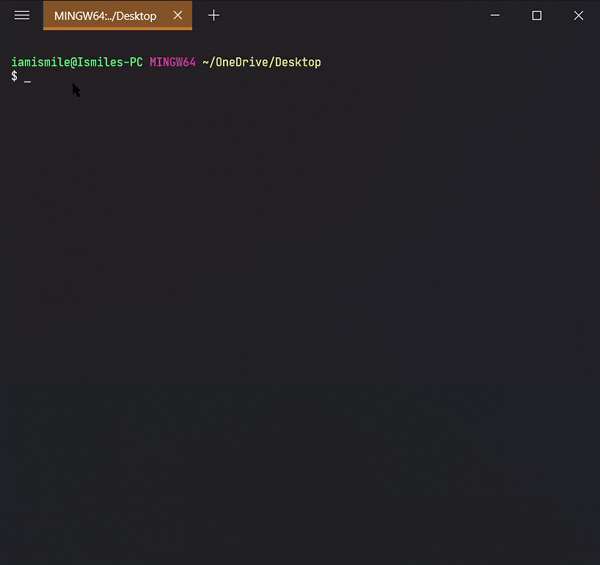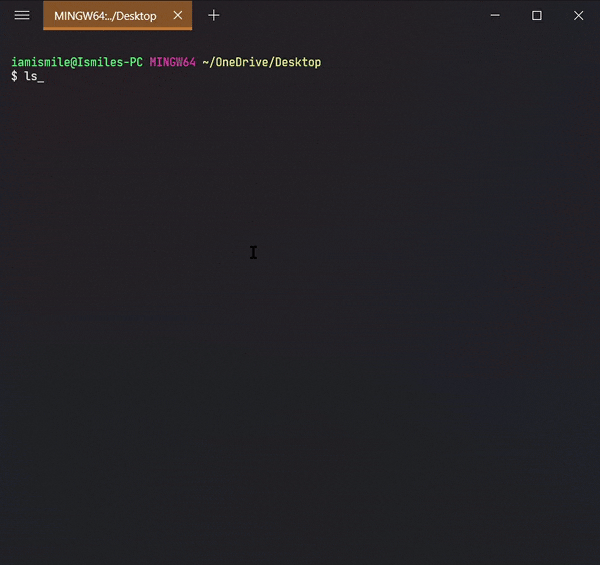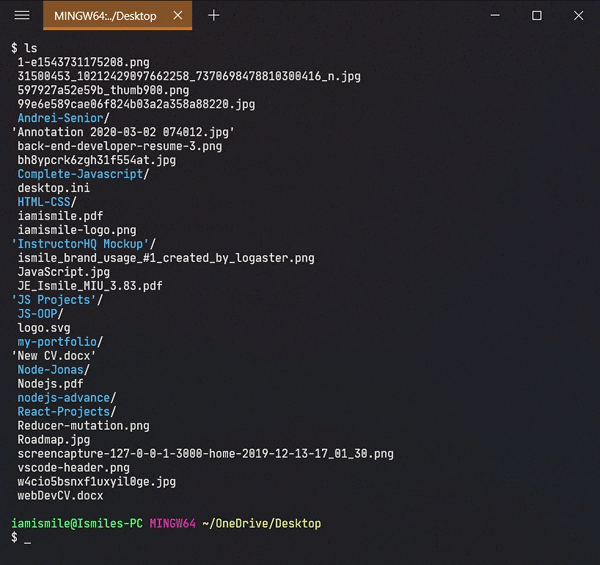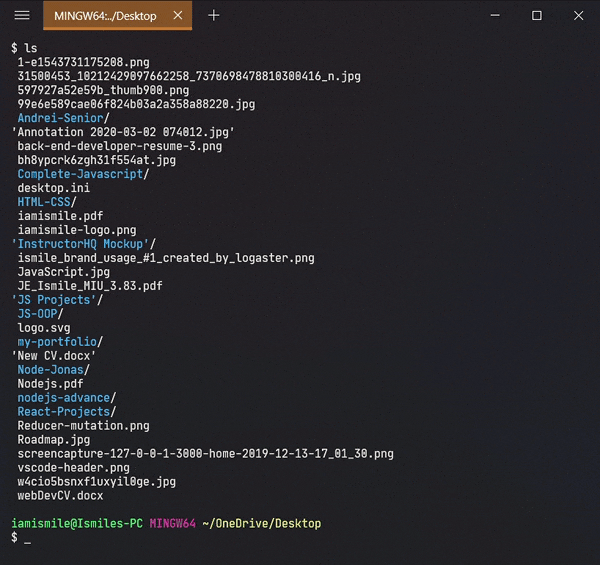
Shows all of my files and directories of my Desktop directory.
-
To show the contents of a directory pass the directory name to
the
lscommand i.e.ls directory_name. -
Some useful
lscommand options:-
OptionDescriptionls -alist all files including hidden file starting with ‘.’ls -llist with the long formatls -lalist long format including hidden files
✔ Create a Directory ➡ mkdir:
We can create a new folder using the
mkdir command.
To use it type
mkdir folder_name.
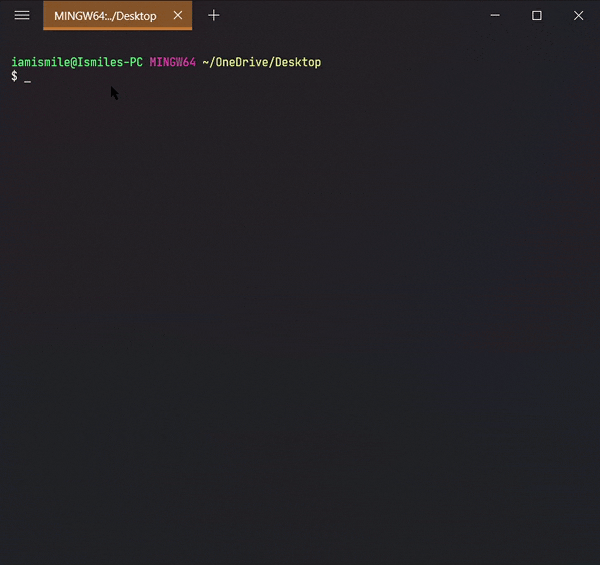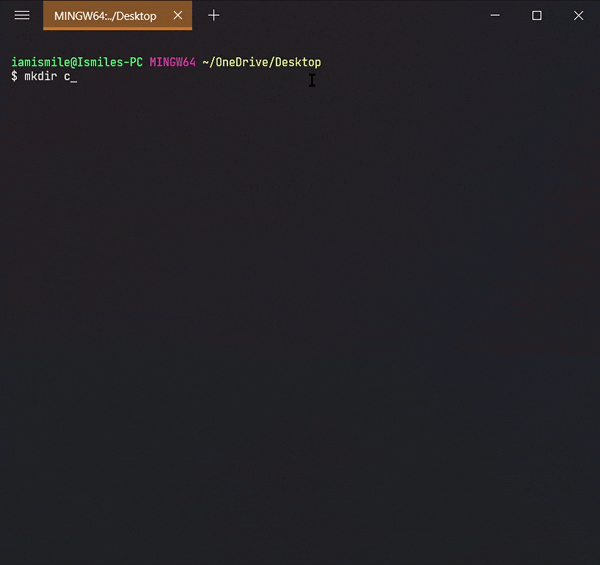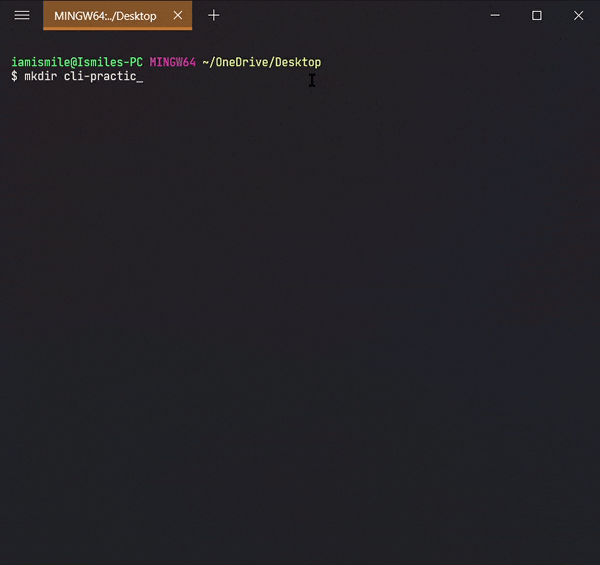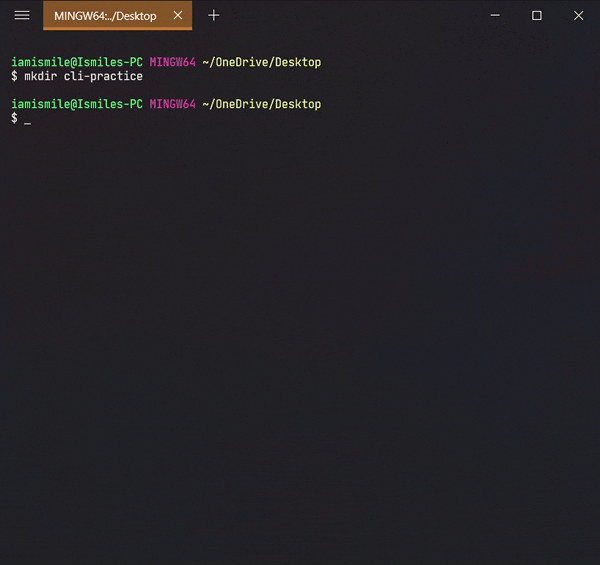
Use ls command
to see the directory is created or not.
I created a cli-practice directory in my working directory i.e. Desktop directory.
✔ Move Between Directories ➡ cd:
It’s used to change directory or to move other directories. To
use it type
cd directory_name.
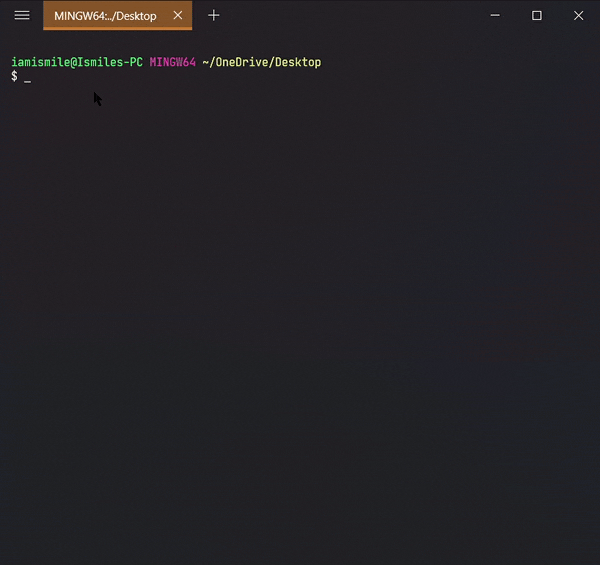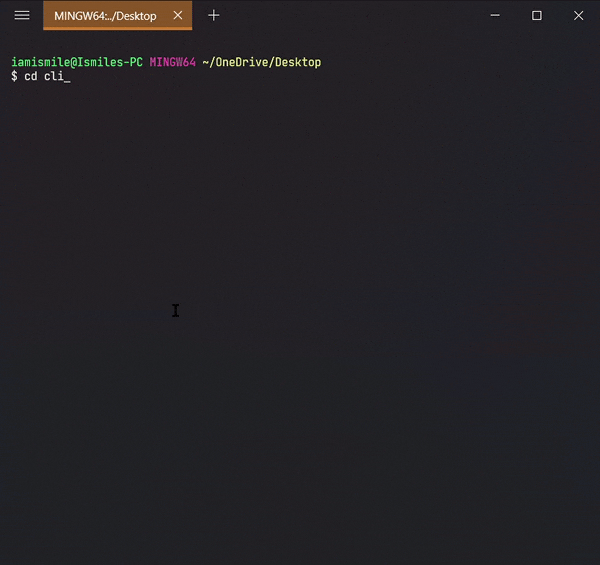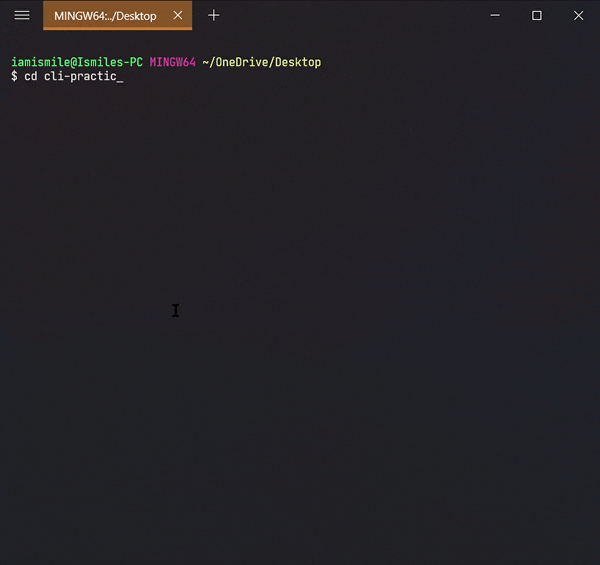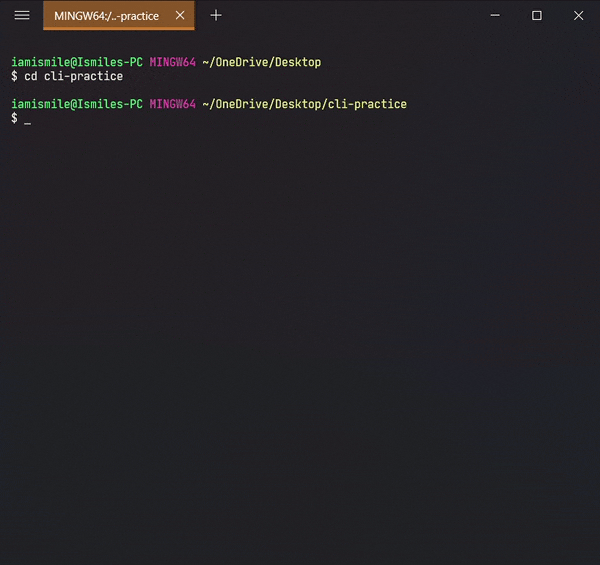
Can use
pwd command to
confirm your directory name.
Changed my directory to the cli-practice directory. And the rest of the tutorial I’m gonna work within this directory.
✔ Parent Directory ➡ ..:
We have seen
cd command to
change directory but if we want to move back or want to move to
the parent directory we can use a special symbol ..
after
cd command,
like cd ..
✔ Create Files ➡ touch:
We can create an empty file by typing
touch file_name. It's going to create a new file in the current directory
(the directory you are currently in) with your provided name.
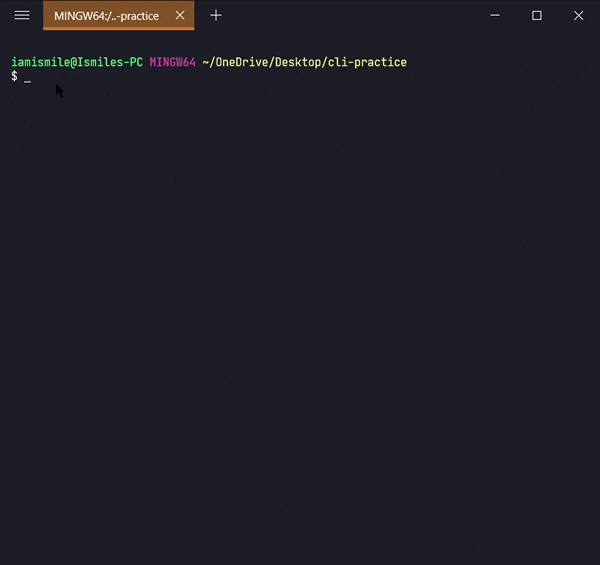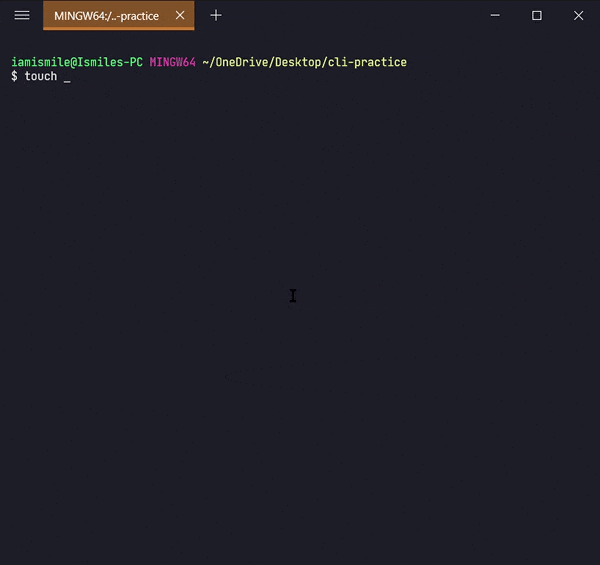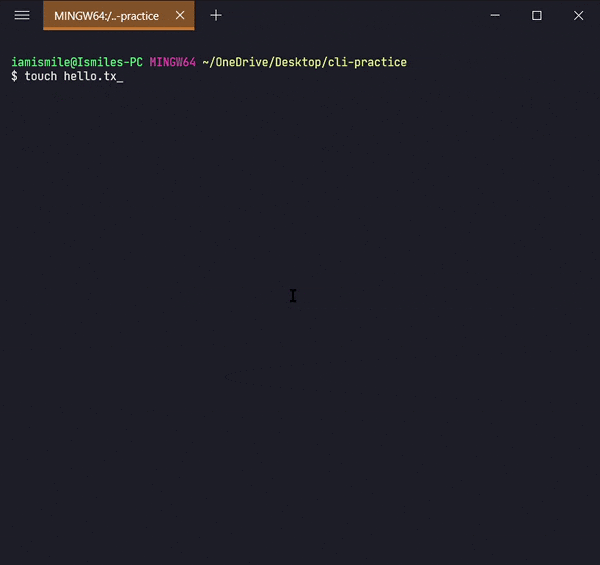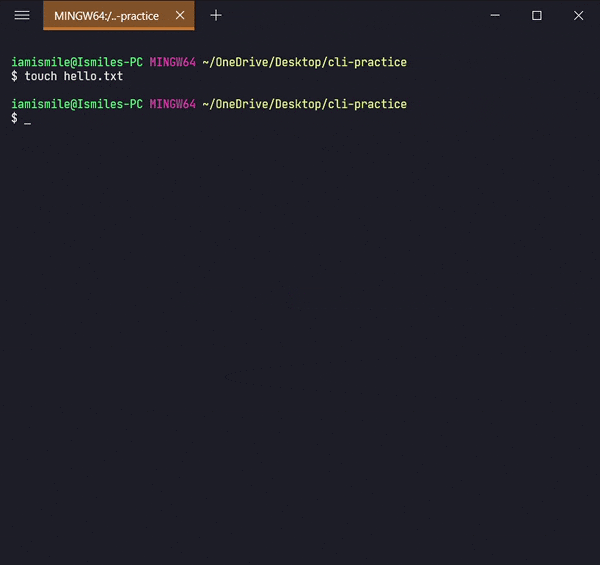
I created a hello.txt file in my current working directory.
Again you can use
ls command to
see the file is created or not.
Now open your hello.txt file in your text editor and write Hello Everyone! into your hello.txt file and save it.
✔ Display the Content of a File ➡ cat:
We can display the content of a file using the
cat command. To
use it type
cat file_name.
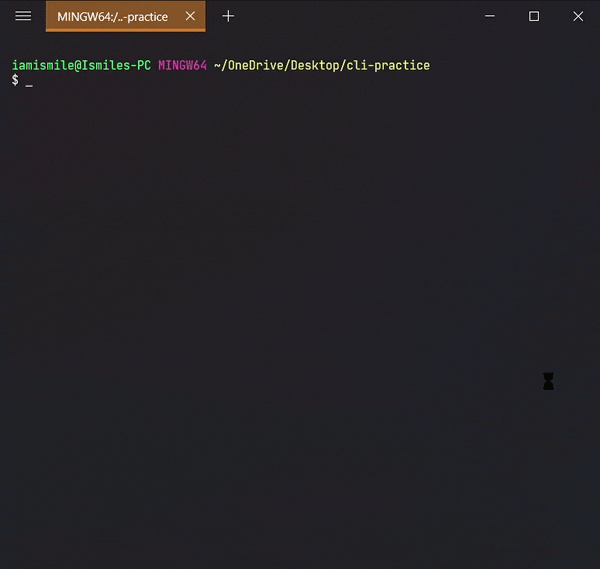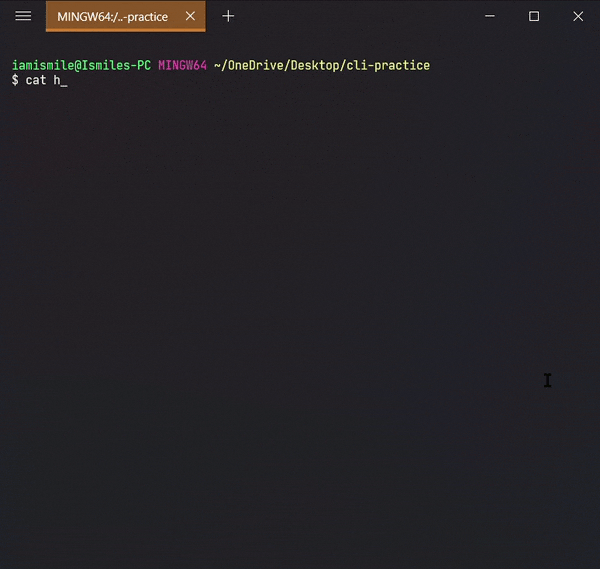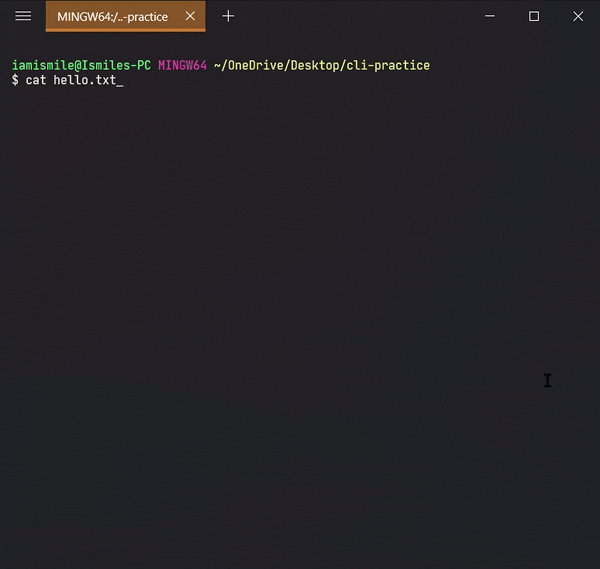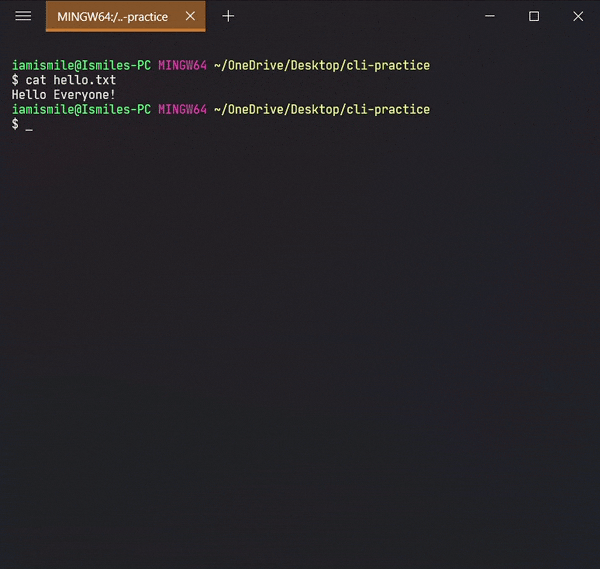
Shows the content of my hello.txt file.
✔ Move Files & Directories ➡ mv:
To move a file and directory, we use
mv command.
By typing
mv file_to_move destination_directory, you can move a file to the specified directory.
By entering
mv directory_to_move destination_directory, you can move all the files and directories under that
directory.
Before using this command, we are going to create two more directories and another txt file in our cli-practice directory.
mkdir html css touch bye.txt
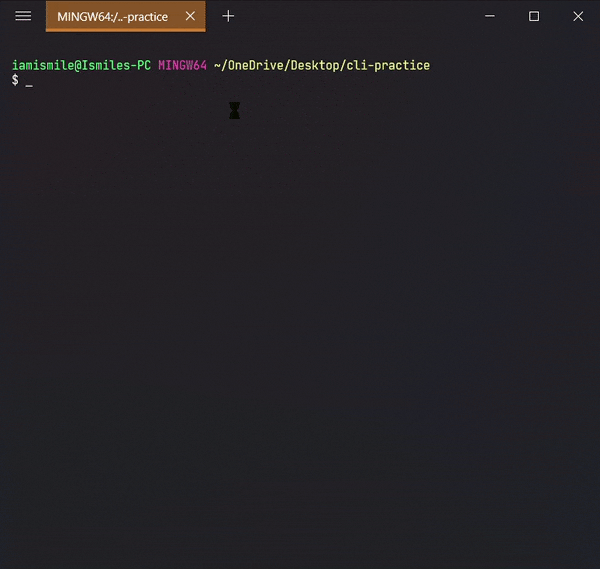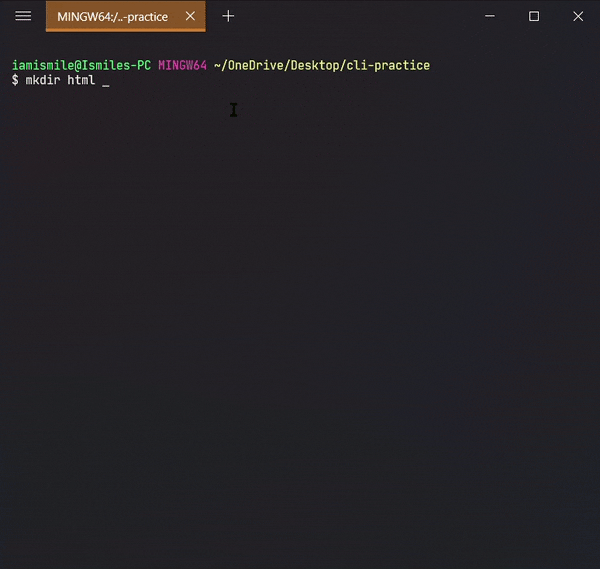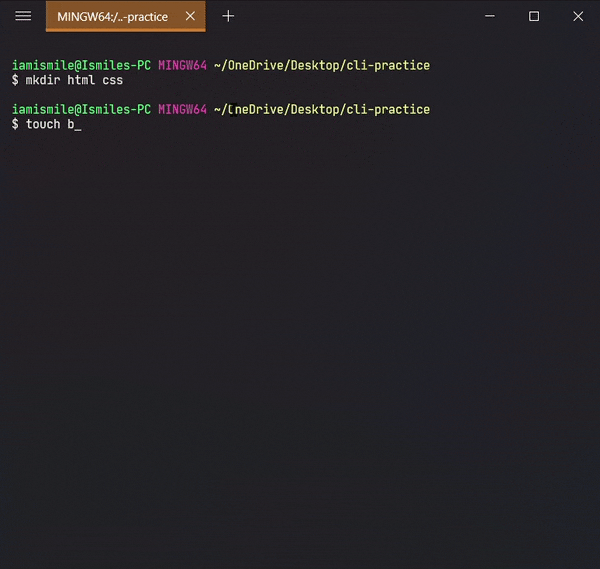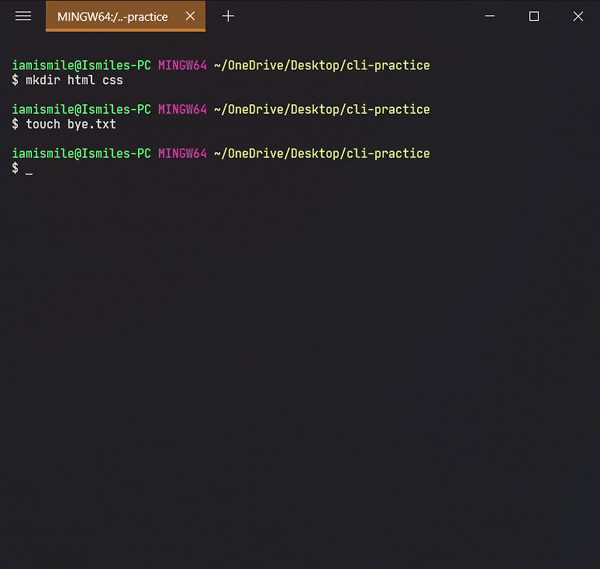
Yes, we can use multiple directories & files names one after another to create multiple directories & files in one command.
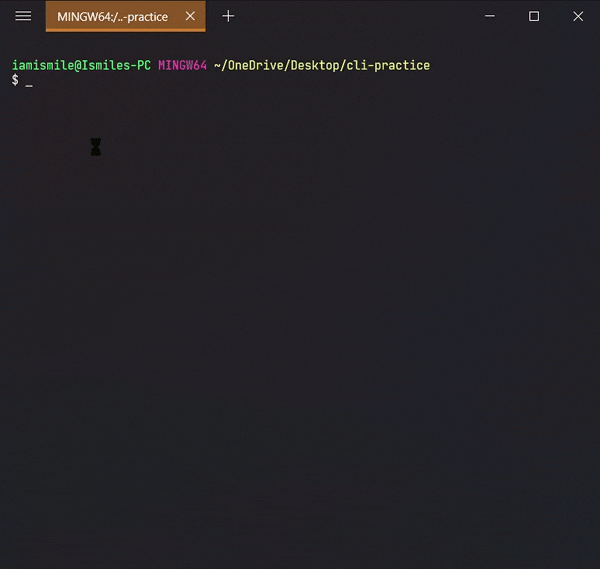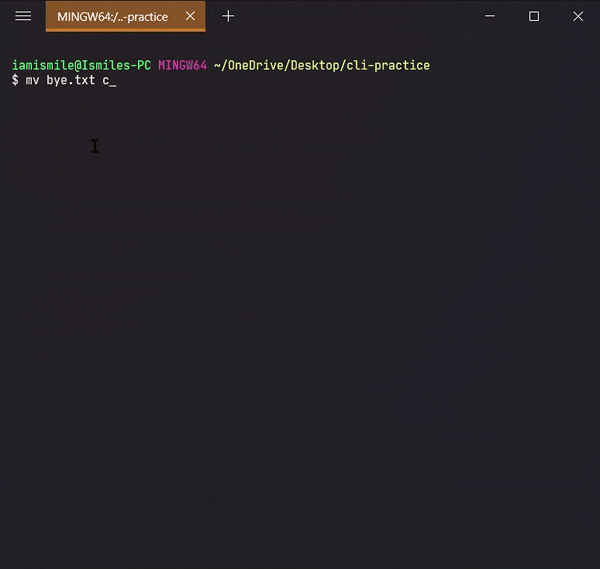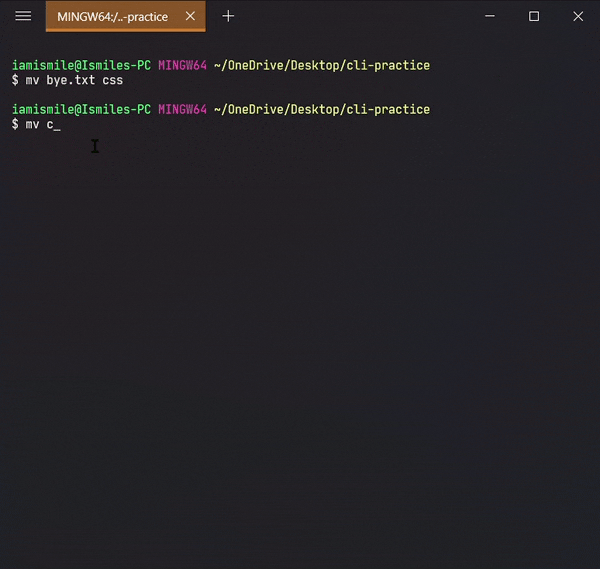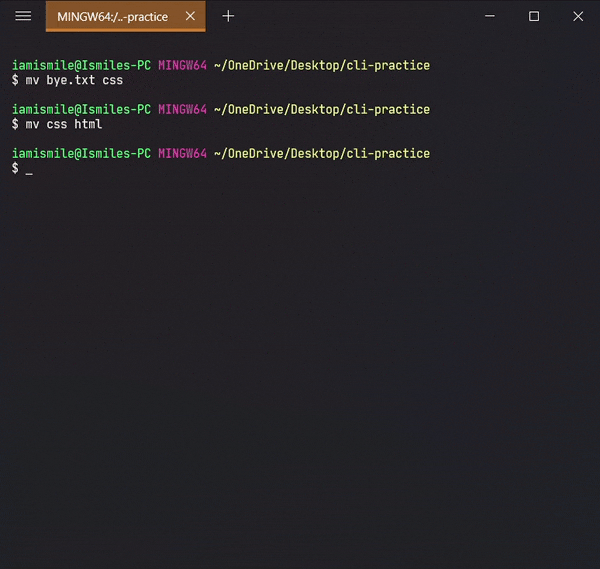
Moved my bye.txt file into my css directory and then moved my css directory into my html directory.
✔ Rename Files & Directories ➡ mv:
mv command can
also be used to rename a file and a directory.
You can rename a file by typing
mv old_file_name new_file_name
& also rename a directory by typing
mv old_directory_name new_directory_name.
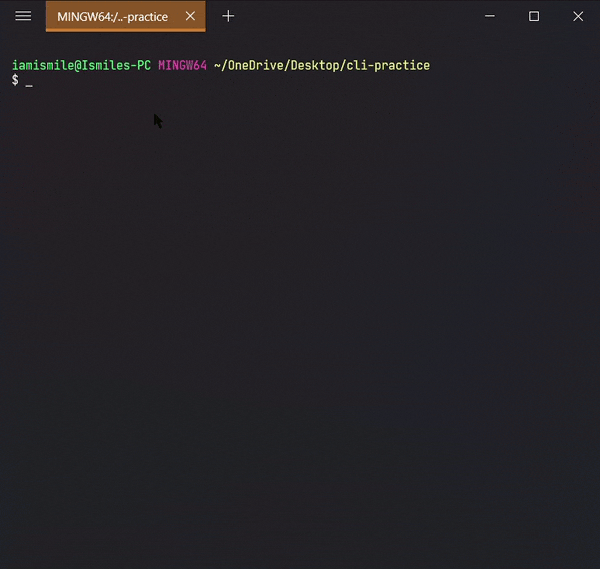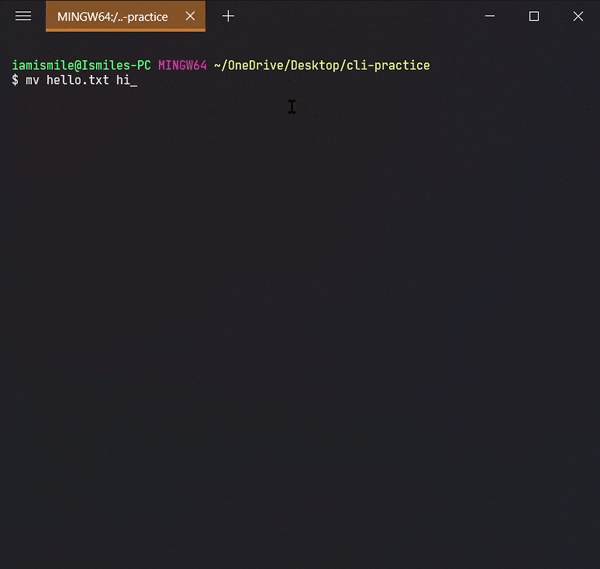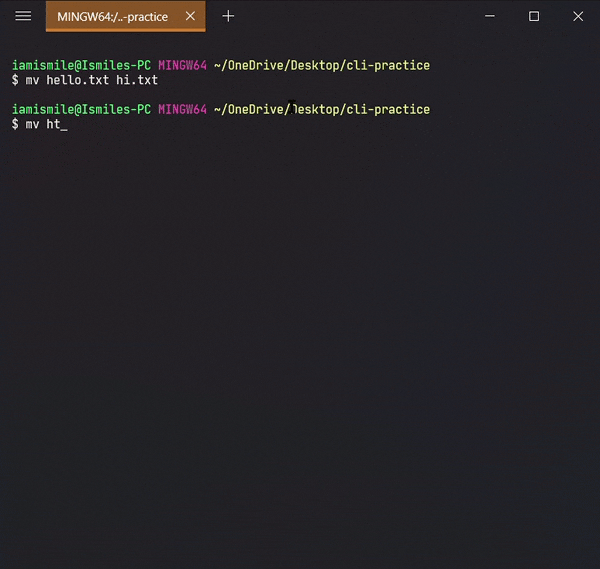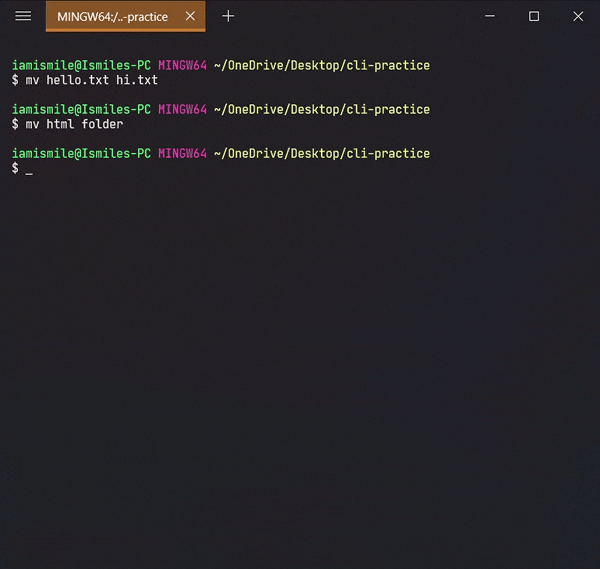
Renamed my hello.txt file to the hi.txt file and html directory to the folder directory.
✔ Copy Files & Directories ➡ cp:
To do this, we use the
cp command.
-
You can copy a file by entering
cp file_to_copy new_file_name.
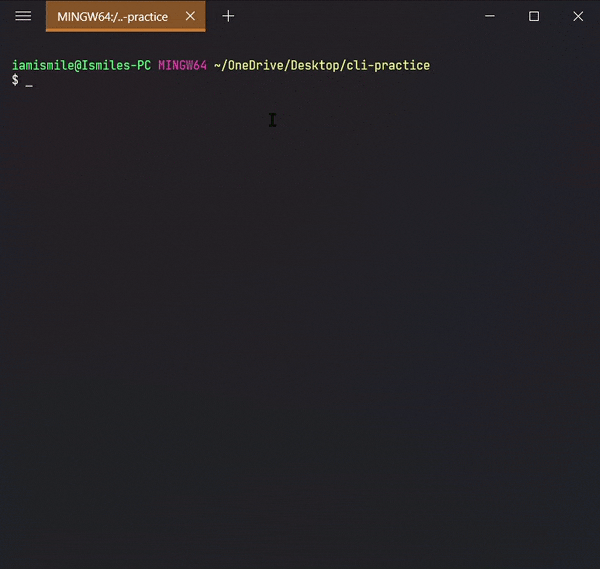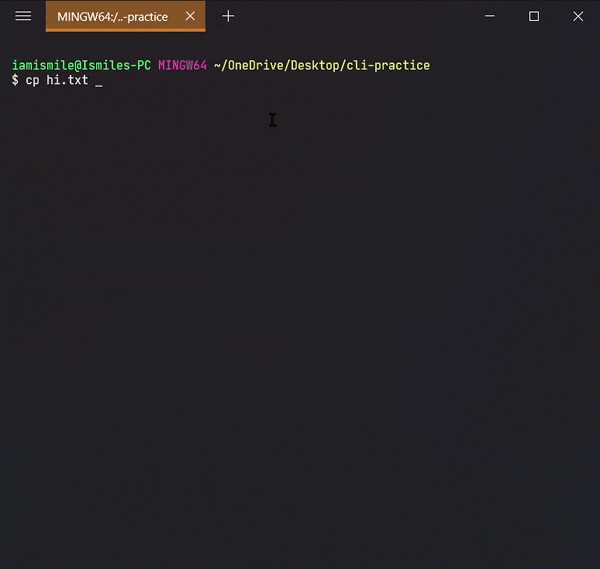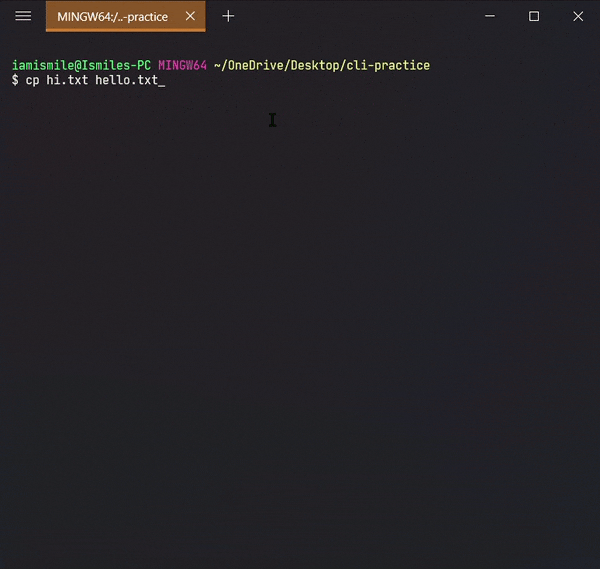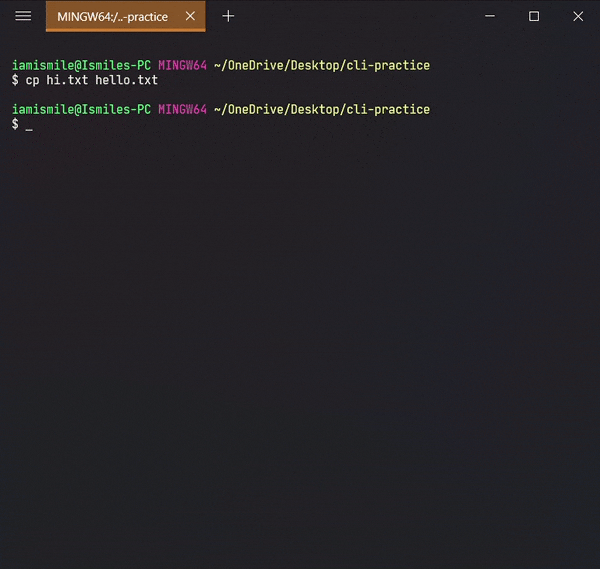
Copied my hi.txt file content into hello.txt file. For confirmation open your hello.txt file in your text editor.
-
You can also copy a directory by adding the
-roption, likecp -r directory_to_copy new_directory_name.
The -r
option for "recursive" means that it will copy all
of the files including the files inside of subfolders.
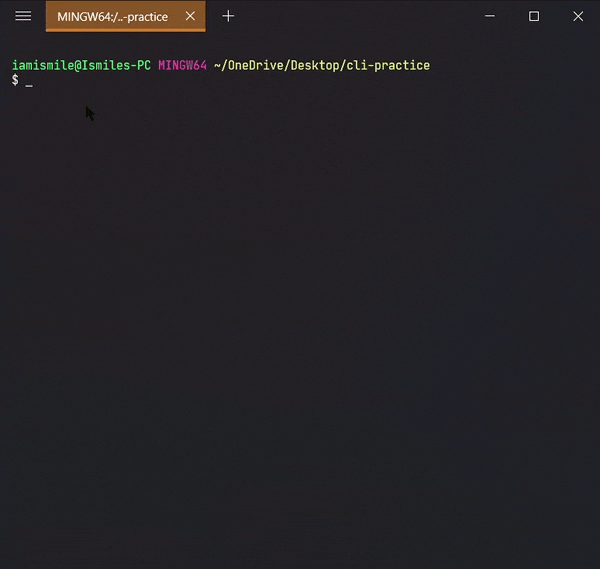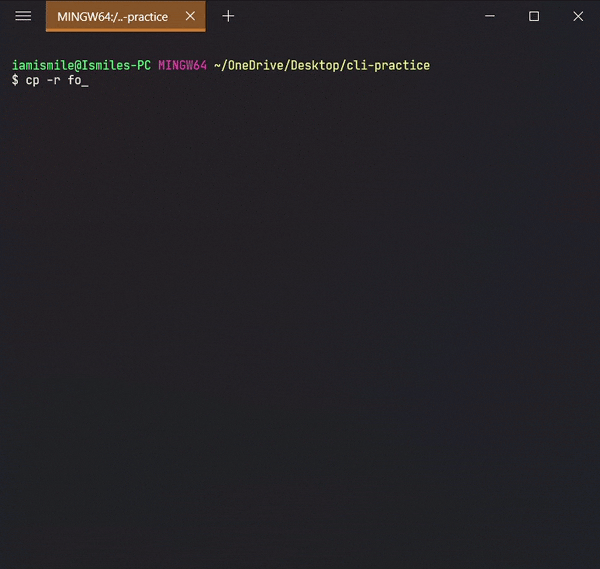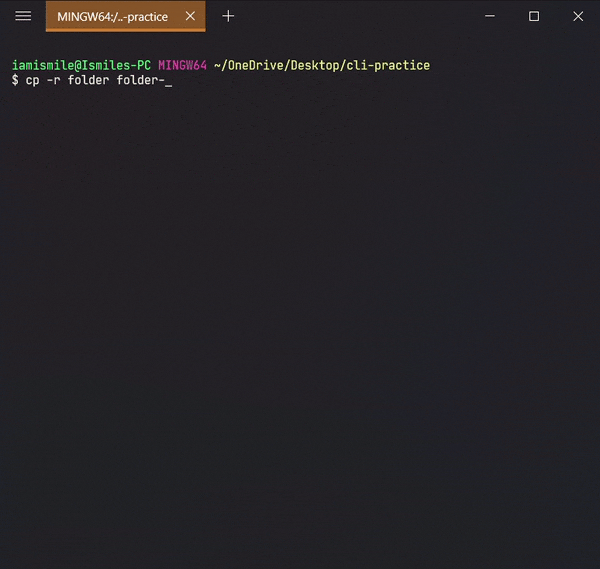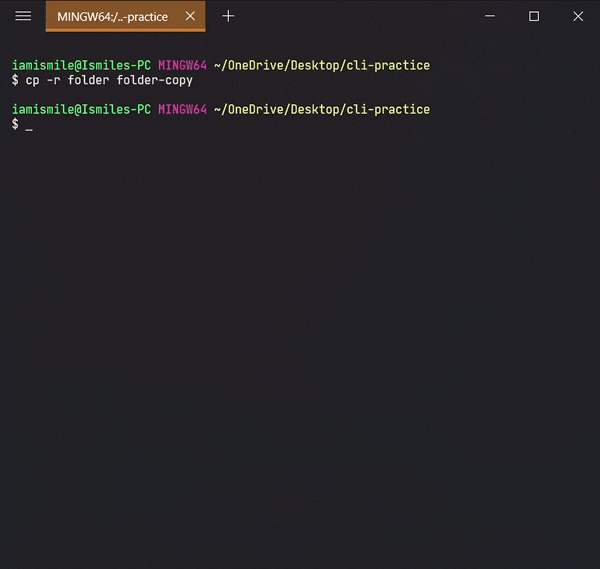
Here I copied all of the files from the folder to folder-copy.
✔ Remove Files & Directories ➡ rm:
To do this, we use the
rm command.
-
To remove a file, you can use the command like
rm file_to_remove.
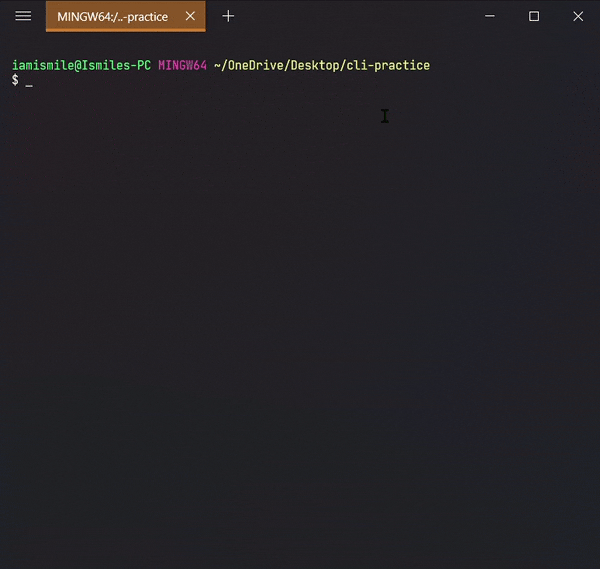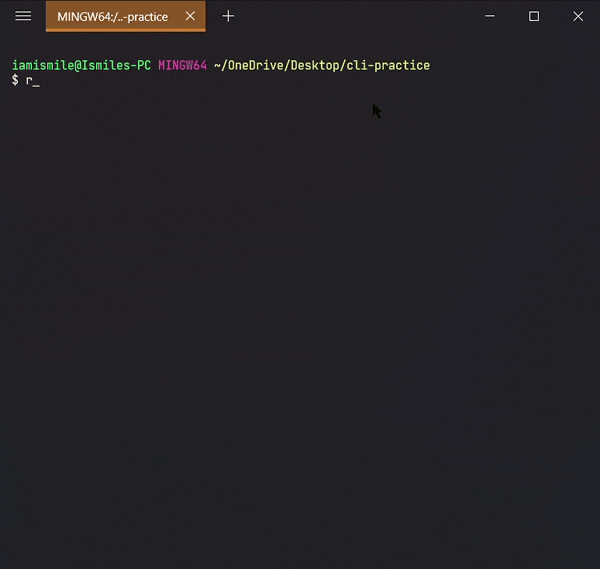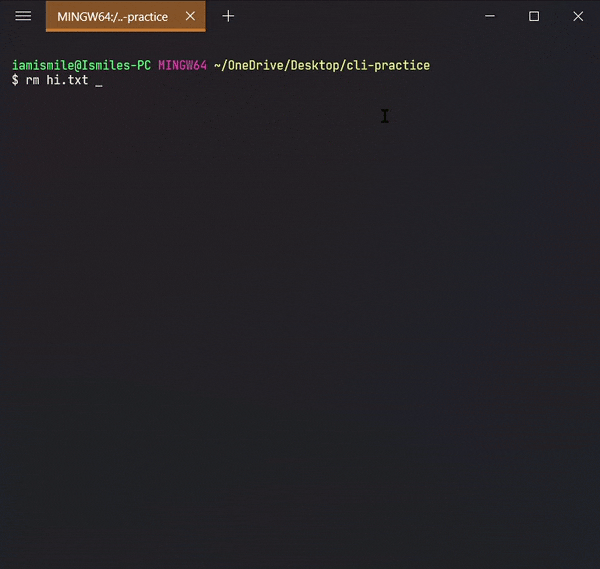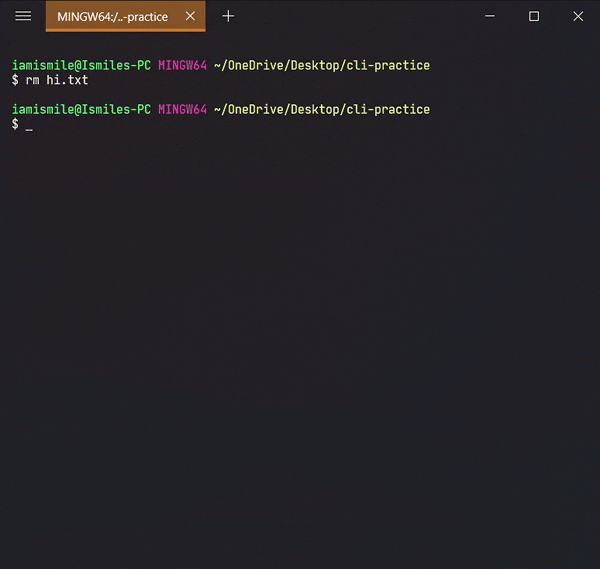
Here I removed my hi.txt file.
-
To remove a directory, use the command like
rm -r directory_to_remove.
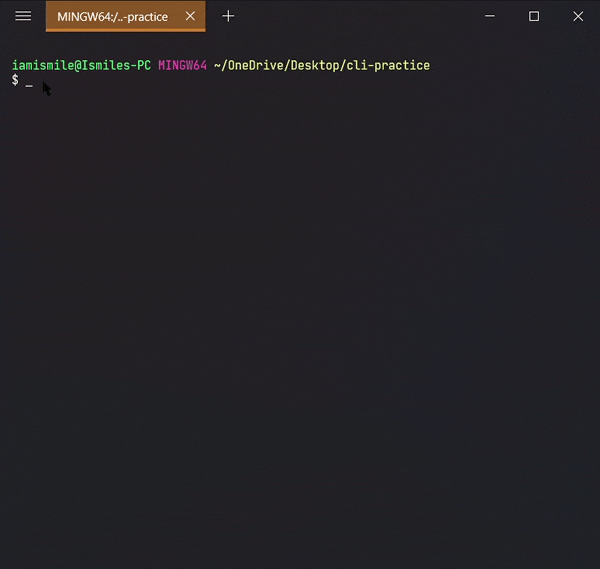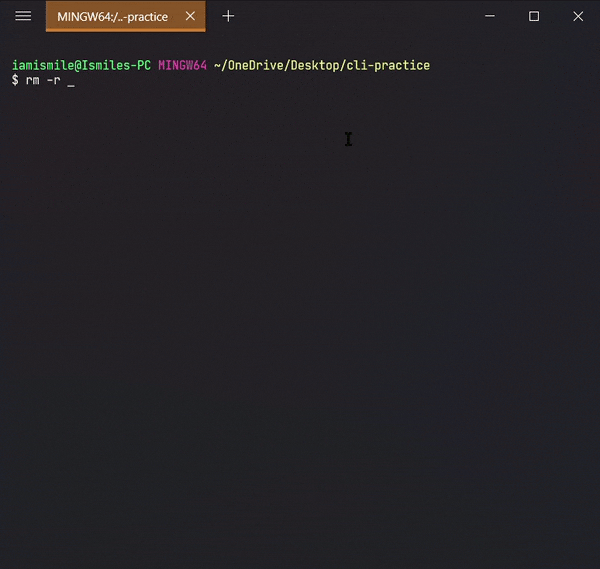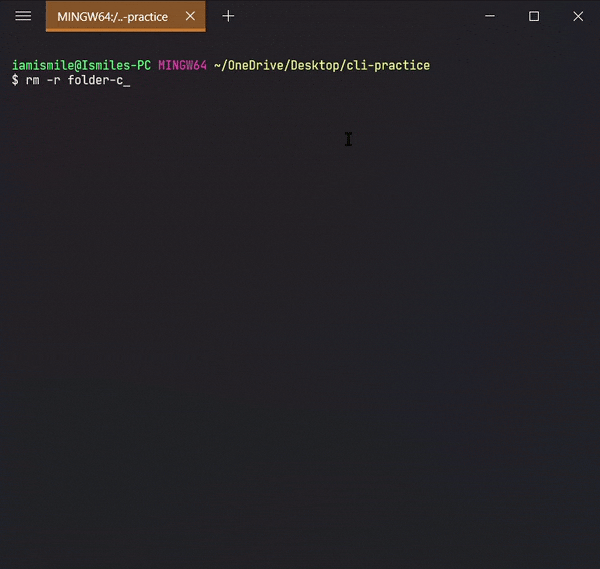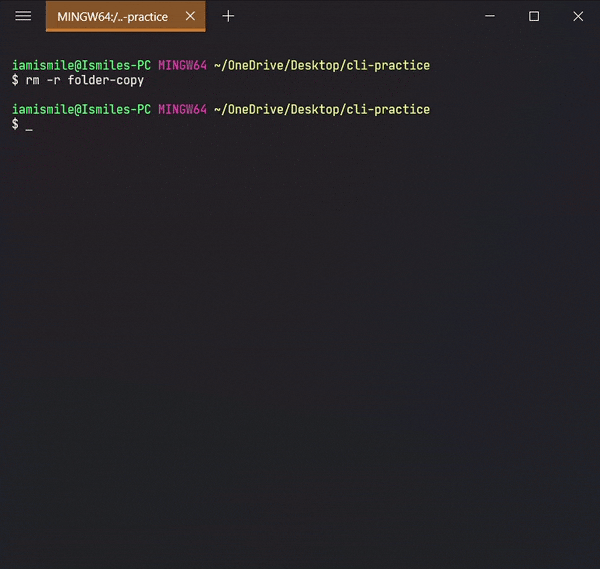
I removed my folder-copy directory from my cli-practice directory i.e. current working directory.
✔ Clear Screen ➡ clear:
Clear command is used to clear the terminal screen.
✔ Home Directory ➡ ~:
The Home directory is represented by
~. The Home
directory refers to the base directory for the user. If we want
to move to the Home directory we can use
cd ~ command.
Or we can only use
cd command.
MY COMMANDS:
1.) Recursively unzip zip files and then delete the archives when finished:
here is a folder containing the before and after… I had to change folder names slightly due to a limit on the length of file-paths in a github repo.
find . -name "*.zip" | while read filename; do unzip -o -d "`dirname "$filename"`" "$filename"; done;
find . -name "*.zip" -type f -print -delete
2.) Install node modules recursively:
npm i -g recursive-install
npm-recursive-install
3.) Clean up unnecessary files/folders in git repo:
find . -empty -type f -print -delete #Remove empty files
# -------------------------------------------------------
find . -empty -type d -print -delete #Remove empty folders
# -------------------------------------------------------
# This will remove .git folders... .gitmodule files as well as .gitattributes and .gitignore files.
find . \( -name ".git" -o -name ".gitignore" -o -name ".gitmodules" -o -name ".gitattributes" \) -exec rm -rf -- {} +
# -------------------------------------------------------
# This will remove the filenames you see listed below that just take up space if a repo has been downloaded for use exclusively in your personal file system (in which case the following files just take up space)# Disclaimer... you should not use this command in a repo that you intend to use with your work as it removes files that attribute the work to their original creators!
find . \( -name "*SECURITY.txt" -o -name "*RELEASE.txt" -o -name "*CHANGELOG.txt" -o -name "*LICENSE.txt" -o -name "*CONTRIBUTING.txt" -name "*HISTORY.md" -o -name "*LICENSE" -o -name "*SECURITY.md" -o -name "*RELEASE.md" -o -name "*CHANGELOG.md" -o -name "*LICENSE.md" -o -name "*CODE_OF_CONDUCT.md" -o -name "\*CONTRIBUTING.md" \) -exec rm -rf -- {} +
In Action:
The following output from my bash shell corresponds to the directory:
Deployment github-pages Navigation Big O notation is the language we use for talking about how long an algorithm takes…github.com
which was created by running the aforementioned commands in in a perfect copy of this directory:
Deployment github-pages Navigation Big O notation is the language we use for talking about how long an algorithm takes…github.com
…..below is the terminal output for the following commands:
pwd
/mnt/c/Users/bryan/Downloads/bash-commands/steps/3-clean-up-fluf/DS-ALGO-OFFICIAL-masterAfter printing the working directory for good measure:
find . -empty -type f -print -deleteThe above command deletes empty files recursively starting from the directory in which it was run:
./CONTENT/DS-n-Algos/File-System/file-utilities/node_modules/line-reader/test/data/empty_file.txt
./CONTENT/DS-n-Algos/_Extra-Practice/free-code-camp/nodejs/http-collect.js
./CONTENT/Resources/Comments/node_modules/mime/.npmignore
./markdown/tree2.md
./node_modules/loadashes6/lodash/README.md
./node_modules/loadashes6/lodash/release.md
./node_modules/web-dev-utils/Markdown-Templates/Markdown-Templates-master/filled-out-readme.md
|01:33:16|bryan@LAPTOP-9LGJ3JGS:[DS-ALGO-OFFICIAL-master] DS-ALGO-OFFICIAL-master_exitstatus:0[╗___________o>The command seen below deletes empty folders recursively starting from the directory in which it was run:
find . -empty -type d -print -deleteThe resulting directories….
|01:33:16|bryan@LAPTOP-9LGJ3JGS:[DS-ALGO-OFFICIAL-master] DS-ALGO-OFFICIAL-master_exitstatus:0[╗___________o>
find . -empty -type d -print -delete
./.git/branches
./.git/objects/info
./.git/refs/tags
|01:33:31|bryan@LAPTOP-9LGJ3JGS:[DS-ALGO-OFFICIAL-master] DS-ALGO-OFFICIAL-master_exitstatus:0[╗___________o>The command seen below deletes .git folders as well as .gitignore, .gitattributes, .gitmodule files
find . \( -name ".git" -o -name ".gitignore" -o -name ".gitmodules" -o -name ".gitattributes" \) -exec rm -rf -- {} +
The command seen below deletes most SECURITY, RELEASE, CHANGELOG, LICENSE, CONTRIBUTING, & HISTORY files that take up pointless space in repo’s you wish to keep exclusively for your own reference.
!!!Use with caution as this command removes the attribution of the work from it’s original authors!!!!!

find . \( -name "*SECURITY.txt" -o -name "*RELEASE.txt" -o -name "*CHANGELOG.txt" -o -name "*LICENSE.txt" -o -name "*CONTRIBUTING.txt" -name "*HISTORY.md" -o -name "*LICENSE" -o -name "*SECURITY.md" -o -name "*RELEASE.md" -o -name "*CHANGELOG.md" -o -name "*LICENSE.md" -o -name "*CODE_OF_CONDUCT.md" -o -name "*CONTRIBUTING.md" \) -exec rm -rf -- {} +4.) Generate index.html file that links to all other files in working directory:
#!/bin/sh
# find ./ | grep -i "\.*$" >files
find ./ | sed -E -e 's/([^ ]+[ ]+){8}//' | grep -i "\.*$">files
listing="files"
out=""
html="index.html"
out="basename $out.html"
html="index.html"
cmd() {
echo ' <!DOCTYPE html>'
echo '<html>'
echo '<head>'
echo ' <meta http-equiv="Content-Type" content="text/html">'
echo ' <meta name="Author" content="Bryan Guner">'
echo '<link rel="stylesheet" href="./assets/prism.css">'
echo ' <link rel="stylesheet" href="./assets/style.css">'
echo ' <script async defer src="./assets/prism.js"></script>'
echo " <title> directory </title>"
echo ""
echo '<style>'
echo ' a {'
echo ' color: black;'
echo ' }'
echo ''
echo ' li {'
echo ' border: 1px solid black !important;'
echo ' font-size: 20px;'
echo ' letter-spacing: 0px;'
echo ' font-weight: 700;'
echo ' line-height: 16px;'
echo ' text-decoration: none !important;'
echo ' text-transform: uppercase;'
echo ' background: #194ccdaf !important;'
echo ' color: black !important;'
echo ' border: none;'
echo ' cursor: pointer;'
echo ' justify-content: center;'
echo ' padding: 30px 60px;'
echo ' height: 48px;'
echo ' text-align: center;'
echo ' white-space: normal;'
echo ' border-radius: 10px;'
echo ' min-width: 45em;'
echo ' padding: 1.2em 1em 0;'
echo ' box-shadow: 0 0 5px;'
echo ' margin: 1em;'
echo ' display: grid;'
echo ' -webkit-border-radius: 10px;'
echo ' -moz-border-radius: 10px;'
echo ' -ms-border-radius: 10px;'
echo ' -o-border-radius: 10px;'
echo ' }'
echo ' </style>'
echo '</head>'
echo '<body>'
echo ""
# continue with the HTML stuff
echo ""
echo ""
echo "<ul>"
awk '{print "<li><a href=\""$1"\">",$1," </a></li>"}' $listing
# awk '{print "<li>"};
# {print " <a href=\""$1"\">",$1,"</a></li> "}' \ $listing
echo ""
echo "</ul>"
echo "</body>"
echo "</html>"
}
cmd $listing --sort=extension >>$html
In Action:
I will use this copy of my Data Structures Practice Site to demonstrate the result:
Deployment github-pages Navigation Big O notation is the language we use for talking about how long an algorithm takes…github.com
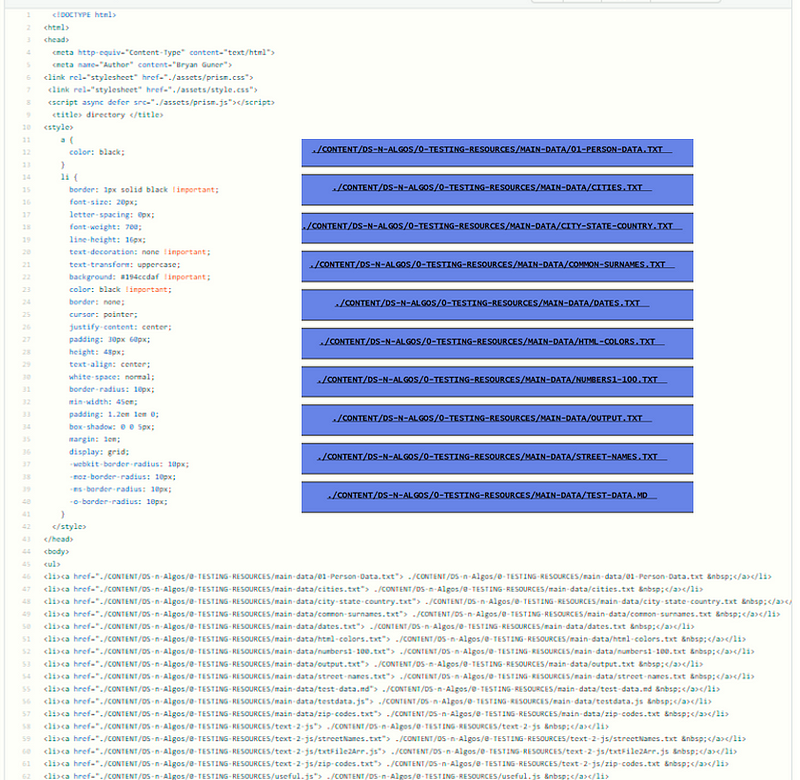
The result is a index.html file that contains a list of links to each file in the directory:
here is a link to and photo of the resulting html file:
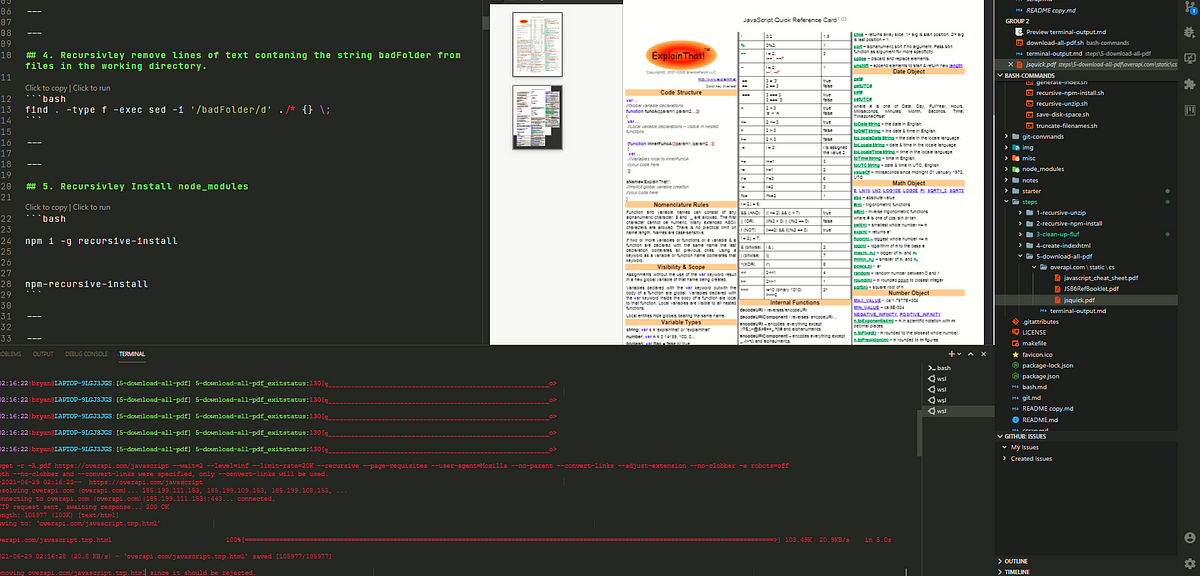
5.) Download all links to a files of a specified extension on a user provided (url) webpage:
wget -r -A.pdf https://overapi.com/gitwget --wait=2 --level=inf --limit-rate=20K --recursive --page-requisites --user-agent=Mozilla --no-parent --convert-links --adjust-extension --no-clobber -e robots=off
The result is stored in this directory:
6.)Recursively remove lines of text containing the string badFolder from files in the working directory.
find . -type f -exec sed -i '/badFolder/d' ./* {} \;
# OR
find . -name 'result.md' -type f -exec sed -i '/badFolder/d' ./* {} \;
As an example I will run this command on a file containing the text:
Hacks Blog
Read more at hacks.mozilla.org
badFolder
badFolder Implementing Private Fields for JavaScript
When implementing a language feature for JavaScript, an implementer must make decisions about how the language in the specification maps to the implementation. Private fields is an example of where the specification language and implementation reality diverge, at least in SpiderMonkey– the JavaScript engine which powers Firefox. To understand more, I’ll explain what private fields are, a couple of models for thinking about them, and explain why our implementation diverges from the specification language.The post Implementing Private Fields for JavaScript appeared first on Mozilla Hacks - the Web developer blog.
Posted Tuesday, June 8, 2021 by Matthew Gaudet
Looking fine with Firefox 89
Firefox 89 has smartened up and brings with it a slimmed-down, slightly more minimalist interface.badFolder Along with this new look, we get some great styling features including a force-colours feature for media queries and better control over how fonts are displayed. The long-awaited top-level await keyword for JavaScript modules is now enabled, as well as the PerformanceEventTiming interface, which is another addition to the performance suite of APIs: 89 really has been working out!The post Looking fine with Firefox 89 appeared first on Mozilla Hacks - the Web developer blog.
badFolder
Posted Tuesday, June 1, 2021 by Chris Mills
badFolder
Improving Firefox stability on Linux
Roughly a year ago at Mozilla we started an effort to improve Firefox stability on Linux. This effort quickly became an example of good synergies between FOSS projects.The post Improving Firefox stability on Linux appeared first on Mozilla Hacks - the Web developer blog.
Posted Wednesday, May 19, 2021 by Gabriele Svelto badFolder
Introducing Firefox’s new Site Isolation Security Architecture
Like any web browser, Firefox loads code from untrusted and potentially hostile websites and runs it on your computer. To protect you against new types of attacks from malicious sites and to meet the security principles of Mozilla, we set out to redesign Firefox on desktop.The post Introducing Firefox’s new Site Isolation Security Architecture appeared first on Mozilla Hacks - the Web developer blog.
Posted Tuesday, May 18, 2021 by Anny Gakhokidze
Pyodide Spin Out and 0.17 Release
We are happy to announce that Pyodide has become an independent and community-driven project. We are also pleased to announce the 0.17 release for Pyodide with many new features and improvements. Pyodide consists of the CPython 3.8 interpreter compiled to WebAssembly which allows Python to run in the browser.The post Pyodide Spin Out and 0.17 Release appeared first on Mozilla Hacks - the Web developer blog. badFolder
Posted Thursday, April 22, 2021 by Teon Brooks
I modified the command slightly to apply only to files called ‘result.md’:
The result is :
Hacks Blog
Read more at hacks.mozilla.org
When implementing a language feature for JavaScript, an implementer must make decisions about how the language in the specification maps to the implementation. Private fields is an example of where the specification language and implementation reality diverge, at least in SpiderMonkey– the JavaScript engine which powers Firefox. To understand more, I’ll explain what private fields are, a couple of models for thinking about them, and explain why our implementation diverges from the specification language.The post Implementing Private Fields for JavaScript appeared first on Mozilla Hacks - the Web developer blog.
Posted Tuesday, June 8, 2021 by Matthew Gaudet
Looking fine with Firefox 89
Posted Tuesday, June 1, 2021 by Chris Mills
Improving Firefox stability on Linux
Roughly a year ago at Mozilla we started an effort to improve Firefox stability on Linux. This effort quickly became an example of good synergies between FOSS projects.The post Improving Firefox stability on Linux appeared first on Mozilla Hacks - the Web developer blog.
Introducing Firefox’s new Site Isolation Security Architecture
Like any web browser, Firefox loads code from untrusted and potentially hostile websites and runs it on your computer. To protect you against new types of attacks from malicious sites and to meet the security principles of Mozilla, we set out to redesign Firefox on desktop.The post Introducing Firefox’s new Site Isolation Security Architecture appeared first on Mozilla Hacks - the Web developer blog.
Posted Tuesday, May 18, 2021 by Anny Gakhokidze
Pyodide Spin Out and 0.17 Release
Posted Thursday, April 22, 2021 by Teon Brooks
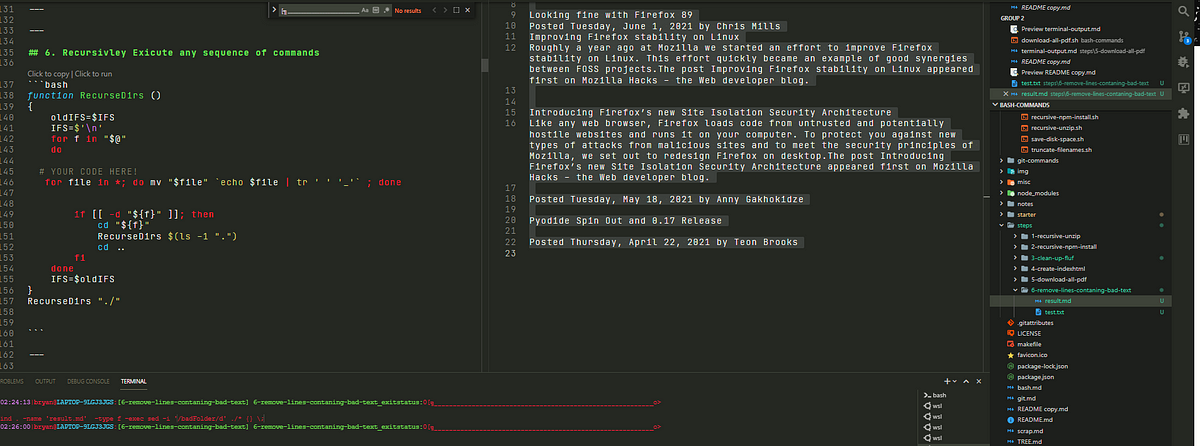
the test.txt and result.md files can be found here:
7.) Execute command recursively:
Here I have modified the command I wish to run recursively to account for the fact that the ‘find’ command already works recursively, by appending the -maxdepth 1 flag…
I am essentially removing the recursive action of the find command…
That way, if the command affects the more deeply nested folders we know the outer RecurseDirs function we are using to run the find/pandoc line once in every subfolder of the working directory… is working properly!
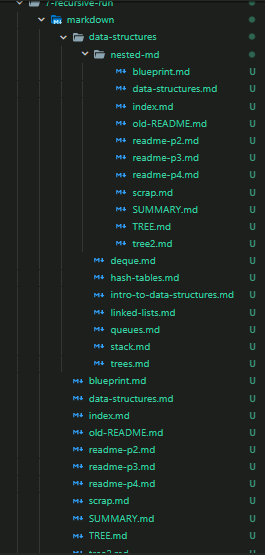
Run in the folder shown to the left… we would expect every .md file to be accompanied by a newly generated html file by the same name.
The results of said operation can be found in the following directory
In Action:
🢃 Below 🢃
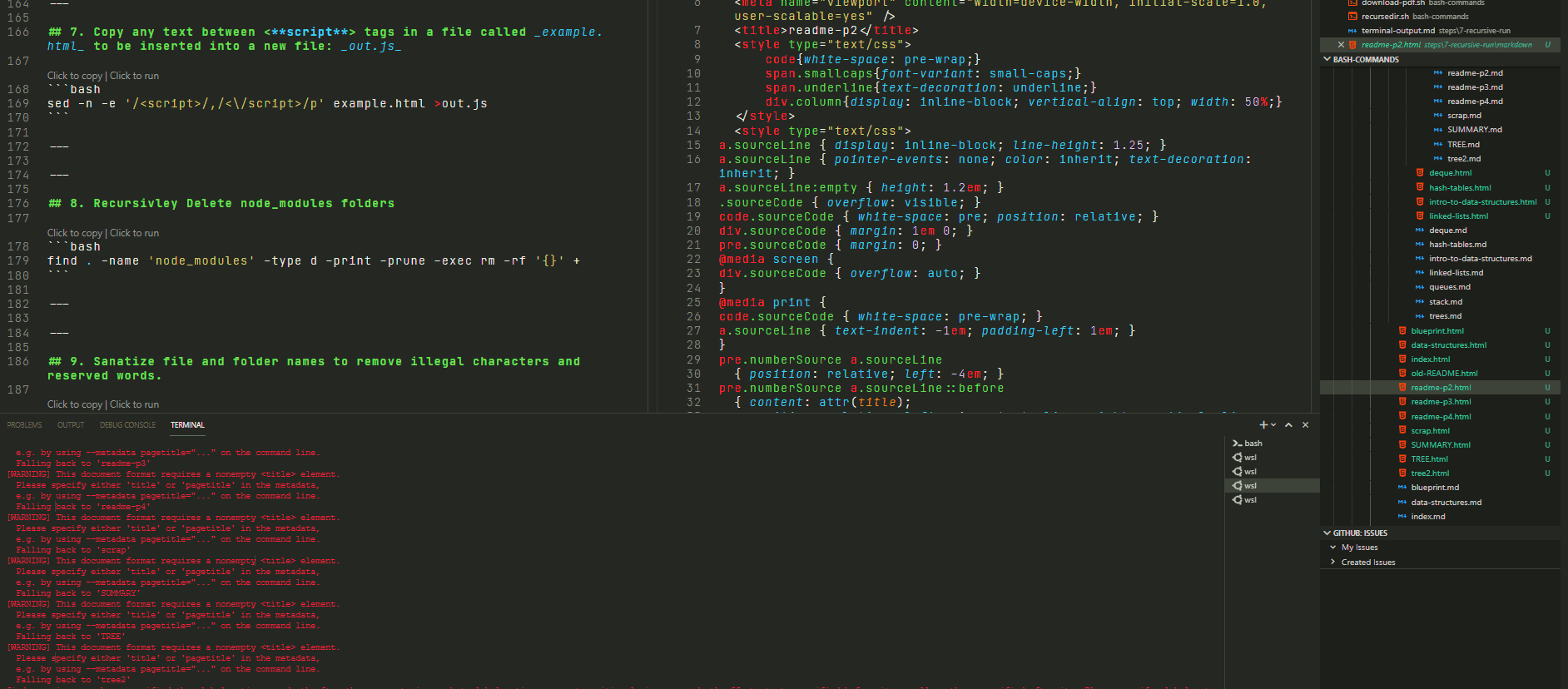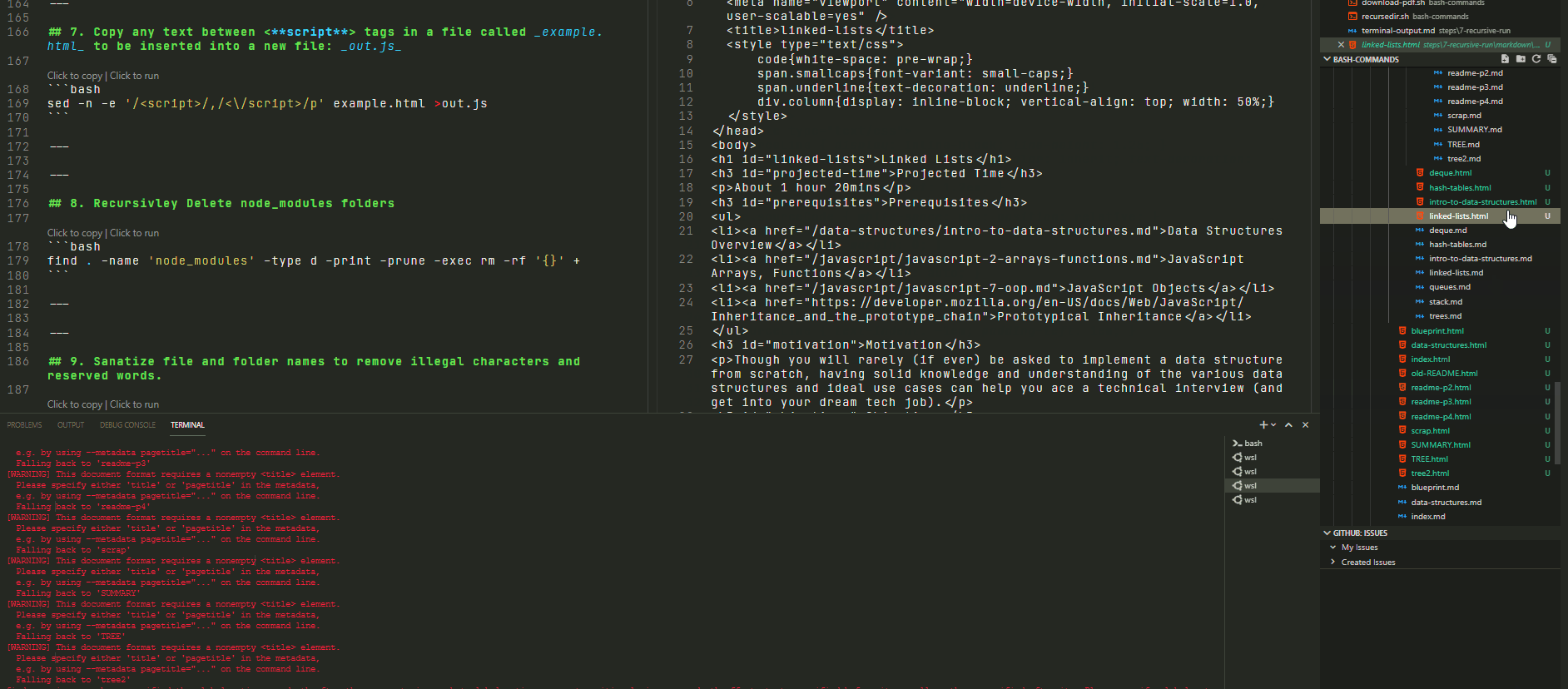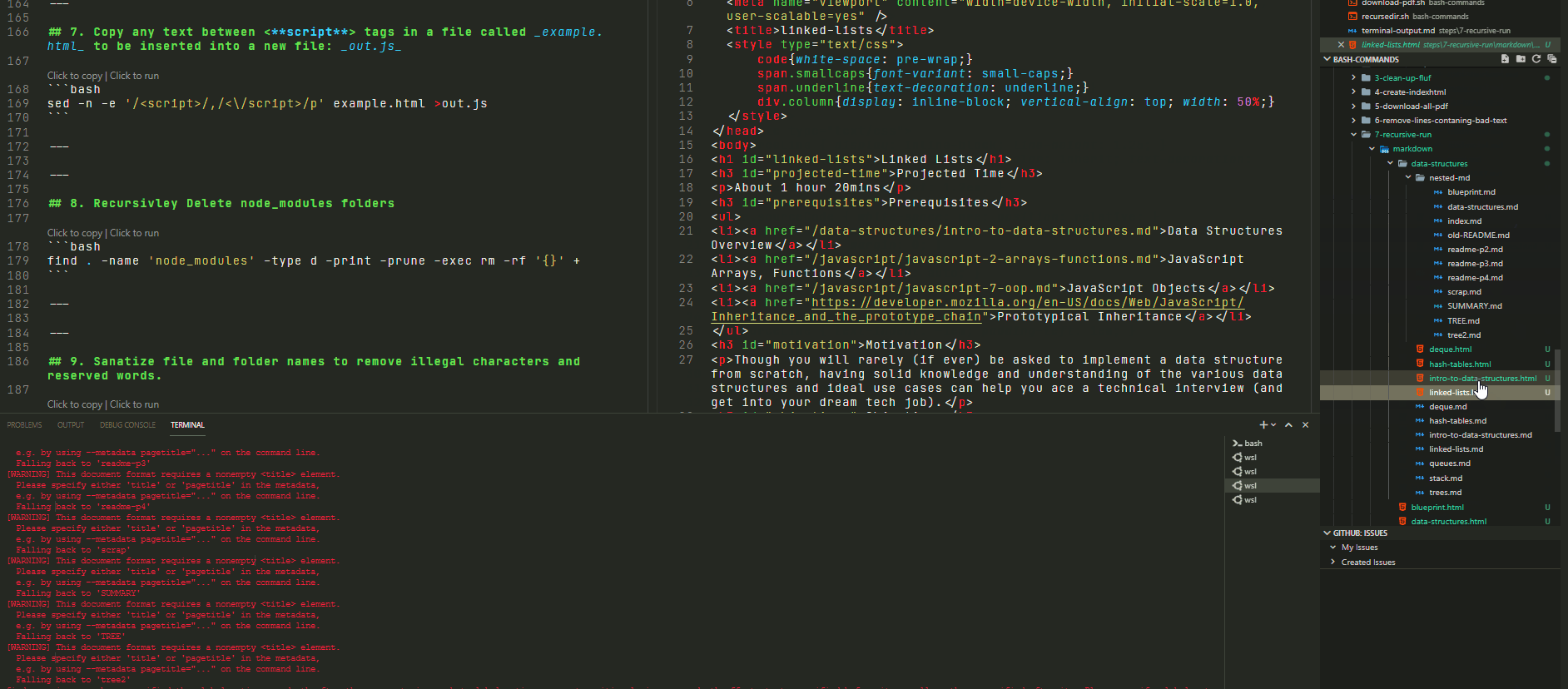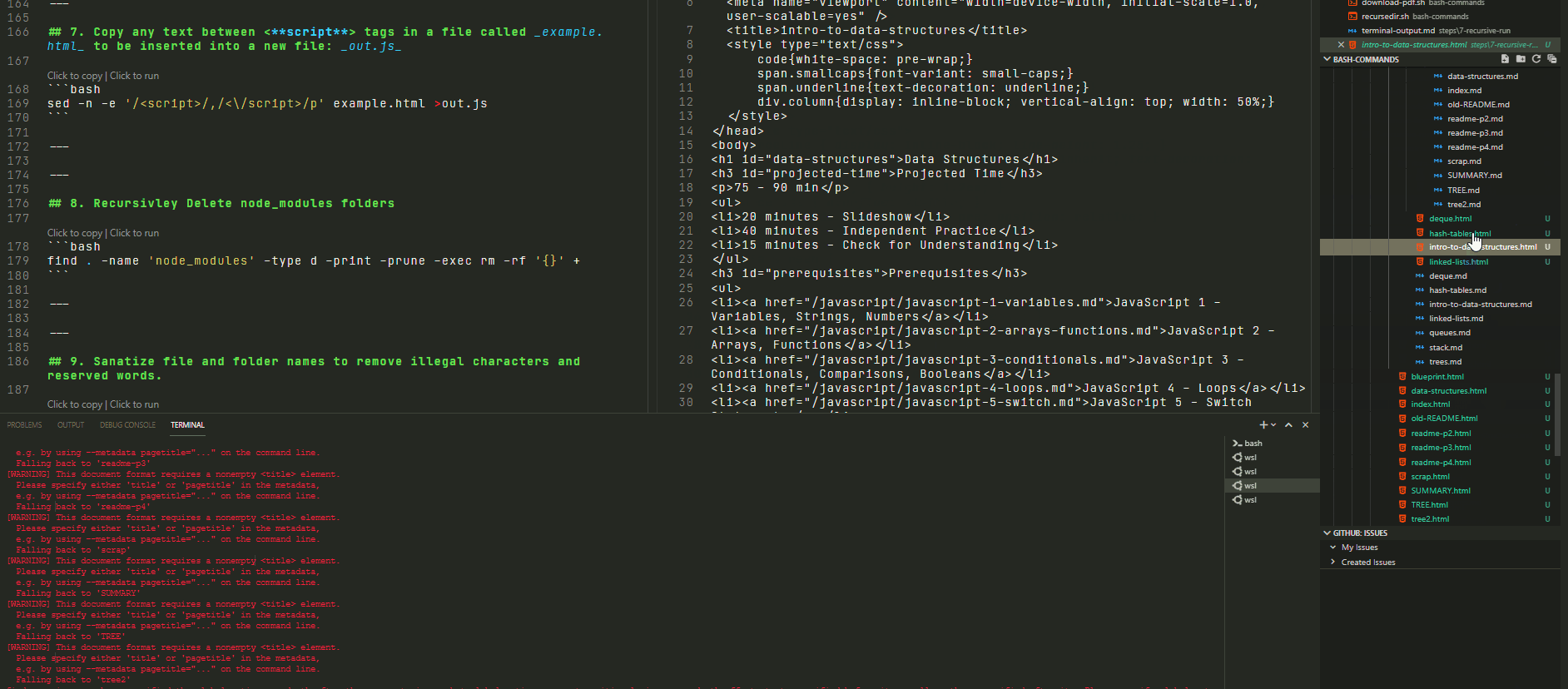
The final result is:
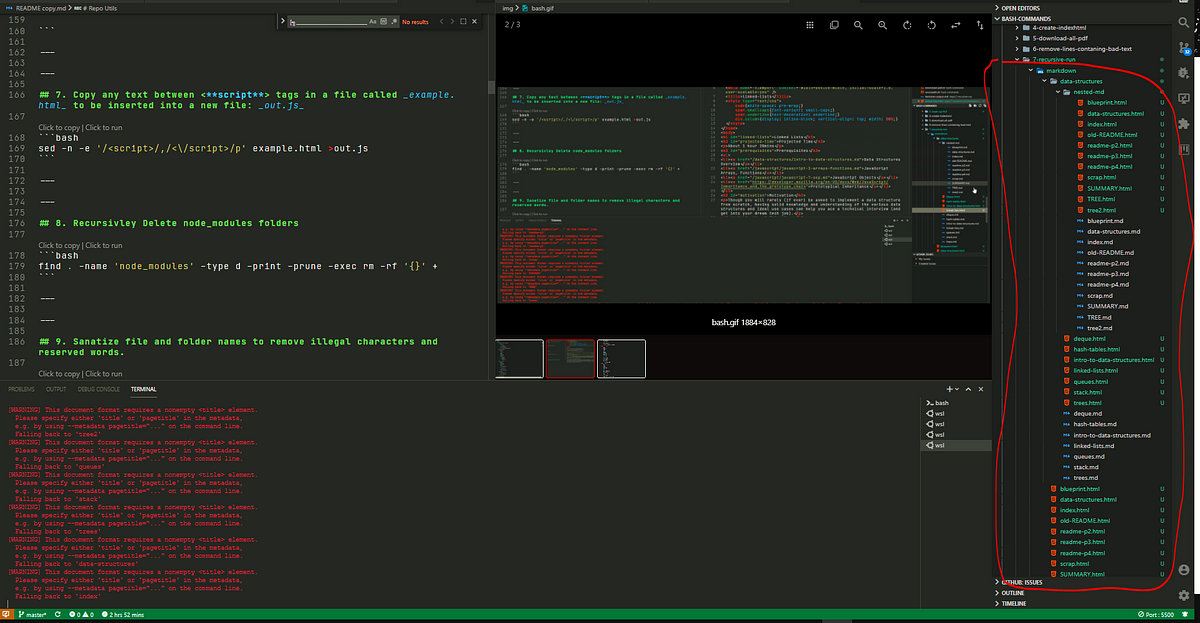
If you want to run any bash script recursively all you have to do is substitue out line #9 with the command you want to run once in every sub-folder.
function RecurseDirs ()
{
oldIFS=$IFS
IFS=$'\n'
for f in "$@"
do
#Replace the line below with your own command!
#find ./ -iname "*.md" -maxdepth 1 -type f -exec sh -c 'pandoc --standalone "${0}" -o "${0%.md}.html"' {} \;
#####################################################
# YOUR CODE BELOW!
#####################################################
if [[ -d "${f}" ]]; then
cd "${f}"
RecurseDirs $(ls -1 ".")
cd ..
fi
done
IFS=$oldIFS
}
RecurseDirs "./"
TBC….
Here are some of the other commands I will cover in greater detail… at a later time:
9. Copy any text between <script> tags in a file called example.html to be inserted into a new file: out.js
sed -n -e '/<script>/,/<\/script>/p' example.html >out.js
10. Recursively Delete node_modules folders
find . -name 'node_modules' -type d -print -prune -exec rm -rf '{}' +
11. Sanatize file and folder names to remove illegal characters and reserved words.
sanitize() {
shopt -s extglob;
filename=$(basename "$1")
directory=$(dirname "$1")
filename_clean=$(echo "$filename" | sed -e 's/[\\/:\*\?"<>\|\x01-\x1F\x7F]//g' -e 's/^\(nul\|prn\|con\|lpt[0-9]\|com[0-9]\|aux\)\(\.\|$\)//i' -e 's/^\.*$//' -e 's/^$/NONAME/')
if (test "$filename" != "$filename_clean")
then
mv -v "$1" "$directory/$filename_clean"
fi
}
export -f sanitize
sanitize_dir() {
find "$1" -depth -exec bash -c 'sanitize "$0"' {} \;
}
sanitize_dir '/path/to/somewhere'
12. Start postgresql in terminal
sudo -u postgres psql
13. Add closing body and script tags to each html file in working directory.
for f in * ; do
mv "$f" "$f.html"
doneecho "<form>
<input type="button" value="Go back!" onclick="history.back()">
</form>
</body></html>" | tee -a *.html
14. Batch Download Videos
#!/bin/bash
link="#insert url here#"
#links were a set of strings with just the index of the video as the variable
num=3
#first video was numbered 3 - weird.
ext=".mp4"
while [ $num -le 66 ]
do
wget $link$num$ext -P ~/Downloads/
num=$(($num+1))
done
15. Change File Extension from ‘.txt’ to .doc for all files in working directory.
sudo apt install rename
rename 's/\.txt$/.doc/' *.txt
16. Recursivley change any file with extension .js.download to .js
find . -name "*.\.js\.download" -exec rename 's/\.js\.download$/.js/' '{}' +
17. Copy folder structure including only files of a specific extension into an ouput Folder
find . -name '*.md' | cpio -pdm './../outputFolder'
Comments
Post a Comment
Share your thoughts!