Postgresql Cheat Sheet
CODEX
PostgreSQL Cheat Sheet
Each table is made up of rows and columns. If you think of a table as a grid, the column go from left to right across the grid and each entry of data is listed down as a row.
Each row in a relational is uniquely identified by a primary key. This can be by one or more sets of column values. In most scenarios it is a single column, such as employeeID.
Every relational table has one primary key. Its purpose is to uniquely identify each row in the database. No two rows can have the same primary key value. The practical result of this is that you can select every single row by just knowing its primary key.
SQL Server UNIQUE constraints allow you to ensure that the data stored in a column, or a group of columns, is unique among the rows in a table.
Although both UNIQUE and PRIMARY KEY constraints enforce the uniqueness of data, you should use the UNIQUE constraint instead of PRIMARY KEY constraint when you want to enforce the uniqueness of a column, or a group of columns, that are not the primary key columns.
Different from PRIMARY KEY constraints, UNIQUE constraints allow NULL. Moreover, UNIQUE constraints treat the NULL as a regular value, therefore, it only allows one NULL per column.

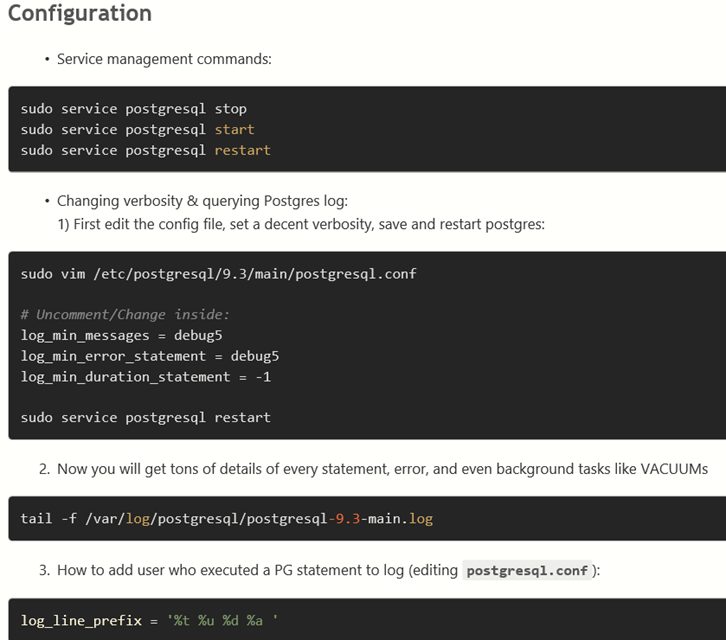

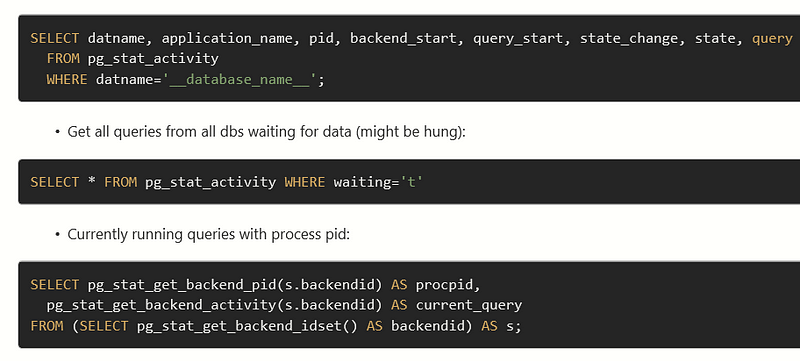
Create a new role:
CREATE ROLE role_name;
Create a new role with a
username and
password:
CREATE ROLE username NOINHERIT LOGIN PASSWORD password;
Change role for the current session to the
new_role:
SET ROLE new_role;
Allow role_1 to
set its role as
role_2:
GRANT role_2 TO role_1;Managing databases
CREATE DATABASE [IF NOT EXISTS] db_name;Delete a database permanently:
DROP DATABASE [IF EXISTS] db_name;Managing tables
Create a new table or a temporary table
CREATE [TEMP] TABLE [IF NOT EXISTS] table_name(
pk SERIAL PRIMARY KEY,
c1 type(size) NOT NULL,
c2 type(size) NULL,
...
);Add a new column to a table:
ALTER TABLE table_name ADD COLUMN new_column_name TYPE;Drop a column in a table:
ALTER TABLE table_name DROP COLUMN column_name;ALTER TABLE table_name RENAME column_name TO new_column_name;Set or remove a default value for a column:
ALTER TABLE table_name ALTER COLUMN [SET DEFAULT value | DROP DEFAULT]Add a primary key to a table.
ALTER TABLE table_name ADD PRIMARY KEY (column,...);Remove the primary key from a table.
ALTER TABLE table_name
DROP CONSTRAINT primary_key_constraint_name;ALTER TABLE table_name RENAME TO new_table_name;Drop a table and its dependent objects:
DROP TABLE [IF EXISTS] table_name CASCADE;Managing views
CREATE OR REPLACE view_name AS
query;CREATE RECURSIVE VIEW view_name(column_list) AS
SELECT column_list;CREATE MATERIALIZED VIEW view_name
AS
query
WITH [NO] DATA;Refresh a materialized view:
REFRESH MATERIALIZED VIEW CONCURRENTLY view_name;Drop a view:
DROP VIEW [ IF EXISTS ] view_name;Drop a materialized view:
DROP MATERIALIZED VIEW view_name;Rename a view:
ALTER VIEW view_name RENAME TO new_name;Managing indexes
Creating an index with the specified name on a table
CREATE [UNIQUE] INDEX index_name
ON table (column,...)Removing a specified index from a table
DROP INDEX index_name;Querying data from tables
Query all data from a table:
SELECT * FROM table_name;Query data from specified columns of all rows in a table:
SELECT column_list
FROM table;Query data and select only unique rows:
SELECT DISTINCT (column)
FROM table;Query data from a table with a filter:
SELECT *
FROM table
WHERE condition;Assign an alias to a column in the result set:
SELECT column_1 AS new_column_1, ...
FROM table;
Query data using the
LIKE
operator:
SELECT * FROM table_name
WHERE column LIKE '%value%'
Query data using the
BETWEEN operator:
SELECT * FROM table_name
WHERE column BETWEEN low AND high;
Query data using the
IN operator:
SELECT * FROM table_name
WHERE column IN (value1, value2,...);
Constrain the returned rows with the
LIMIT
clause:
SELECT * FROM table_name
LIMIT limit OFFSET offset
ORDER BY column_name;Query data from multiple using the inner join, left join, full outer join, cross join and natural join:
SELECT *
FROM table1
INNER JOIN table2 ON conditions
SELECT *
FROM table1
LEFT JOIN table2 ON conditions
SELECT *
FROM table1
FULL OUTER JOIN table2 ON conditions
SELECT *
FROM table1
CROSS JOIN table2;
SELECT *
FROM table1
NATURAL JOIN table2;Return the number of rows of a table.
SELECT COUNT (*)
FROM table_name;Sort rows in ascending or descending order:
SELECT select_list
FROM table
ORDER BY column ASC [DESC], column2 ASC [DESC],...;
Group rows using
GROUP BY
clause.
SELECT *
FROM table
GROUP BY column_1, column_2, ...;
Filter groups using the
HAVING
clause.
SELECT *
FROM table
GROUP BY column_1
HAVING condition;Set operations
Combine the result set of two or more queries with
UNION
operator:
SELECT * FROM table1
UNION
SELECT * FROM table2;
Minus a result set using
EXCEPT
operator:
SELECT * FROM table1
EXCEPT
SELECT * FROM table2;Get intersection of the result sets of two queries:
SELECT * FROM table1
INTERSECT
SELECT * FROM table2;Modifying data
Insert a new row into a table:
INSERT INTO table(column1,column2,...)
VALUES(value_1,value_2,...);Insert multiple rows into a table:
INSERT INTO table_name(column1,column2,...)
VALUES(value_1,value_2,...),
(value_1,value_2,...),
(value_1,value_2,...)...Update data for all rows:
UPDATE table_name
SET column_1 = value_1,
...;
Update data for a set of rows specified by a condition in the
WHERE clause.
UPDATE table
SET column_1 = value_1,
...
WHERE condition;Delete all rows of a table:
DELETE FROM table_name;Delete specific rows based on a condition:
DELETE FROM table_name
WHERE condition;Performance
Show the query plan for a query:
EXPLAIN query;Show and execute the query plan for a query:
EXPLAIN ANALYZE query;Collect statistics:
ANALYZE table_name;Postgres & JSON:
Creating the DB and the Table
DROP DATABASE IF EXISTS books_db;
CREATE DATABASE books_db WITH ENCODING='UTF8' TEMPLATE template0;DROP TABLE IF EXISTS books;CREATE TABLE books (
id SERIAL PRIMARY KEY,
client VARCHAR NOT NULL,
data JSONb NOT NULL
);Populating the DB
INSERT INTO books(client, data) values( 'Joe', '{ "title": "Siddhartha", "author": { "first_name": "Herman", "last_name": "Hesse" } }' ); INSERT INTO books(client, data) values('Jenny', '{ "title": "Bryan Guner", "author": { "first_name": "Jack", "last_name": "Kerouac" } }'); INSERT INTO books(client, data) values('Jenny', '{ "title": "100 años de soledad", "author": { "first_name": "Gabo", "last_name": "Marquéz" } }');
Lets see everything inside the table books:
SELECT * FROM books;Output:

-> operator
returns values out of JSON columns
Selecting 1 column:
SELECT client,
data->'title' AS title
FROM books;Output:

Selecting 2 columns:
SELECT client,
data->'title' AS title, data->'author' AS author
FROM books;Output:

-> vs ->>
The
-> operator
returns the original JSON type (which might be an object),
whereas
->>
returns text.
Return NESTED objects
You can use the
-> to return
a nested object and thus chain the operators:
SELECT client,
data->'author'->'last_name' AS author
FROM books;Output:

Filtering
Select rows based on a value inside your JSON:
SELECT
client,
data->'title' AS title
FROM books
WHERE data->'title' = '"Bryan Guner"';
Notice WHERE uses
-> so we
must compare to JSON
'"Bryan Guner"'
Or we could use
->> and
compare to
'Bryan Guner'
Output:

Nested filtering
Find rows based on the value of a nested JSON object:
SELECT
client,
data->'title' AS title
FROM books
WHERE data->'author'->>'last_name' = 'Kerouac';Output:

A real world example
CREATE TABLE events (
name varchar(200),
visitor_id varchar(200),
properties json,
browser json
);We’re going to store events in this table, like pageviews. Each event has properties, which could be anything (e.g. current page) and also sends information about the browser (like OS, screen resolution, etc). Both of these are completely free form and could change over time (as we think of extra stuff to track).
INSERT INTO events VALUES (
'pageview', '1',
'{ "page": "/" }',
'{ "name": "Chrome", "os": "Mac", "resolution": { "x": 1440, "y": 900 } }'
);
INSERT INTO events VALUES (
'pageview', '2',
'{ "page": "/" }',
'{ "name": "Firefox", "os": "Windows", "resolution": { "x": 1920, "y": 1200 } }'
);
INSERT INTO events VALUES (
'pageview', '1',
'{ "page": "/account" }',
'{ "name": "Chrome", "os": "Mac", "resolution": { "x": 1440, "y": 900 } }'
);
INSERT INTO events VALUES (
'purchase', '5',
'{ "amount": 10 }',
'{ "name": "Firefox", "os": "Windows", "resolution": { "x": 1024, "y": 768 } }'
);
INSERT INTO events VALUES (
'purchase', '15',
'{ "amount": 200 }',
'{ "name": "Firefox", "os": "Windows", "resolution": { "x": 1280, "y": 800 } }'
);
INSERT INTO events VALUES (
'purchase', '15',
'{ "amount": 500 }',
'{ "name": "Firefox", "os": "Windows", "resolution": { "x": 1280, "y": 800 } }'
);Now lets select everything:
SELECT * FROM events;Output:

JSON operators + PostgreSQL aggregate functions
Using the JSON operators, combined with traditional PostgreSQL aggregate functions, we can pull out whatever we want. You have the full might of an RDBMS at your disposal.
- Lets see browser usage:
-
SELECT browser->>'name' AS browser, count(browser) FROM events GROUP BY browser->>'name';
Output:

- Total revenue per visitor:
SELECT visitor_id,
SUM(CAST(properties->>'amount' AS integer)) AS
total FROM events WHERE
CAST(properties->>'amount' AS integer) > 0
GROUP BY visitor_id;
Output:

- Average screen resolution
-
SELECT AVG(CAST(browser->'resolution'->>'x' AS integer)) AS width, AVG(CAST(browser->'resolution'->>'y' AS integer)) AS height FROM events;
Output:

If you found this guide helpful feel free to checkout my github/gists where I host similar content:
Web Developer, Electrical Engineer JavaScript | CSS | Bootstrap | Python | React | Node.js | Express | Sequelize…github.com
Or Checkout my personal Resource Site:
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
Instantly share code, notes, and snippets. Web Developer, Electrical Engineer JavaScript | CSS | Bootstrap | Python |…gist.github.com
Web Developer, Electrical Engineer JavaScript | CSS | Bootstrap | Python | React | Node.js | Express | Sequelize…github.com
Comments
Post a Comment
Share your thoughts!